System Design Interview Prep: SQL vs NoSQL Databases
Technical Program Management Kevin Jin • Last updated
Kevin Jin • Last updated 
In system design interviews, you will often have to choose what database to use, and these databases are split into SQL and NoSQL types. SQL and NoSQL databases each have their own strengths (+) and weaknesses (-), and should be chosen appropriately based on the use case.
SQL Databases
(+) Relationships
SQL databases, also known as relational databases, allows easy querying on relationships between data among multiple tables. These relationships are defined using primary and foreign key columns. Table relationships are really important for effectively organizing and structuring a lot of different data. SQL, as a query language, is also both very powerful for fetching data and easy to learn.
(+) Structured Data
Data is structured using SQL schemas that define the columns and tables in a database. The data model and format of the data must be known before storing anything, which reduces room for potential error.
(+) ACID
Another benefit of SQL databases is that they are ACID (Atomicity, Consistency, Isolation, Durability) compliant, and they ensure that by supporting transactions. SQL transactions are groups of statements that are executed atomically. This means that they are either all executed, or not executed at all if any statement in the group fails. A simple example of a SQL transaction is written below:
BEGIN TRANSACTION transfer_money_1922;
UPDATE balances SET balance = balance - 25 WHERE account_id = 10;
UPDATE balances SET balance = balance + 25 WHERE account_id = 155;
COMMIT TRANSACTION;
$25 is being transferred from one account balance to another.
(-) Structured Data
Since columns and tables have to be created ahead of time, SQL databases take more time to set up compared to NoSQL databases. SQL databases are also not effective for storing and querying unstructured data (where the format is unknown).
(-) Difficult to Scale
Because of the relational nature of SQL databases, they are difficult to scale horizontally. For read-heavy systems, it’s straightforward to provision multiple read-only replicas (with master-slave replication), but for write-heavy systems, the only option oftentimes is to vertically scale the database up, which is generally more expensive than provisioning additional servers.
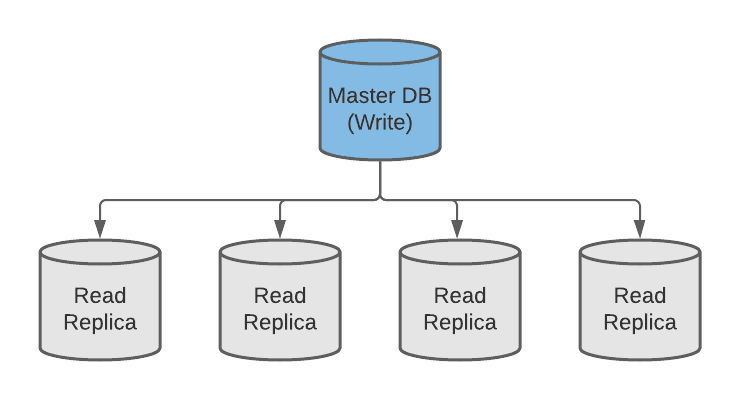
Master-Slave Replication
Related Note 1: By increasing the number of read replicas, a trade-off is made between consistency and availability. Having more read servers leads to higher availability, but in turn, sacrifices data consistency (provided that the updates are asynchronous) since there is a higher chance of accessing stale data. This follows the CAP theorem, which will be discussed more as a separate topic.
Related Note 2: It’s not impossible to horizontally scale write-heavy SQL databases, looking at Google Spanner and CockroachDB, but it’s a very challenging problem and makes for a highly complex database architecture.
Examples of Popular SQL databases: MySQL, PostgreSQL, Microsoft SQL Server, Oracle, CockroachDB.
NoSQL Databases
(+) Unstructured Data
NoSQL databases do not support table relationships, and data is usually stored in documents or as key-value pairs. This means that NoSQL databases are more flexible, simpler to set up and a better choice for storing unstructured data.
(+) Horizontal Scaling
Without table relationships, data in NoSQL databases can be sharded across different data stores, allowing for distributed databases. This makes horizontal scaling much easier, and very large amounts of data can be stored without having to purchase a single, expensive server. NoSQL databases can flexibly support both read-heavy and write-heavy systems. With data spread out across multiple shards/servers, hashing and consistent hashing are very important techniques for determining which shard(s) to route application queries to.
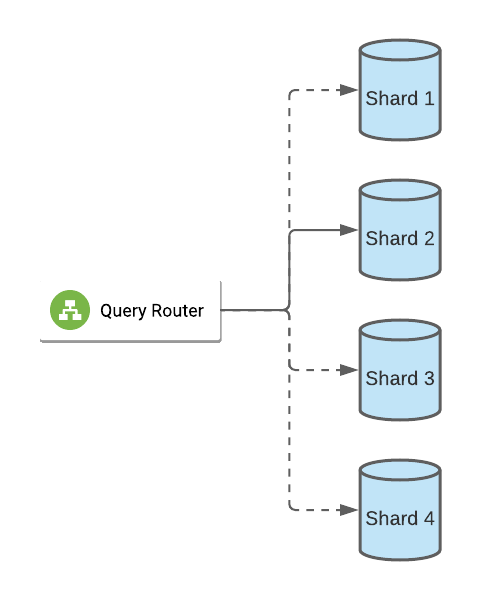
MongoDB uses a query router, which is a reverse proxy that accepts a query and routes it to the appropriate shard(s). The router then sends the query response back to the calling application. Note that the query router is very similar to a load balancer.
(-) Eventual Consistency
NoSQL databases are typically designed for distributed use cases, and write-heavy systems can be supported by having multiple write shards for the same data partition (called peer-to-peer replication). However, the tradeoff is a loss of strong consistency. After a write to a shard in a distributed NoSQL cluster, there’ll be a small delay before that update can be propagated to other replicas. During this time, reading from a replica can result in accessing stale data.
This weakness of the data eventually being up-to-date, a.k.a eventual consistency, was actually seen earlier with master-slave replication (which can be used for SQL or NoSQL). Eventual consistency isn’t exactly a fault of NoSQL databases, but distributed databases in general. A single shard NoSQL database can be strongly consistent, but to fully take advantage of the scalability benefits of NoSQL, the database should be set up as a distributed cluster.
Examples of Popular NoSQL Databases: MongoDB, Redis, DynamoDB, Cassandra, CouchDB
Short Exercises
Question 1
The goal is to build a service for tens of millions of Amazon shoppers, which will store each shopper’s past 100 viewed products. The stored data is shopper specific, and should be used for targeted product advertisements towards that shopper. It’s fine if this data is a little out-of-date. What kind of database should be used?
Hint: The last sentence mentions it’s fine if the data is a bit stale.
Hint 2: There is a lot of data that needs to be stored.
Solution:
NoSQL
Question 2
A company has been experiencing some scaling pains as the engineering team has been building a lot of new microservices and many of them make read requests to the main SQL database regarding customer metrics. The goal is to build a cache service that sits in front of the database to offload some of these read queries. This cache service should look up the query and if it hasn’t been cached in the last 10 minutes, then query the database for the result and cache it. Else, the cache service just gets the result from the cache without querying the main database. What kind of database should be used to build the cache?
Hint: This database should be able to look up the cached result by the SQL query (string).
Hint 2: The stored data is non-relational.
Solution:
NoSQL
Question 3
The goal is to build a service at PayPal that can allow users to apply for loans through the app. The service needs a database to store loan applications. In addition to the loan amount, the application also needs information regarding the user’s current balance and prior transaction history. What kind of database should be used?
Hint: This is a financial application where data consistency is very important.
Hint 2: Data about the loan, user’s balance and transaction history all need to be stored, and there’s relationships between these data.
Solution:
SQL
Book time with a Technical Program Manager coach
- Mock interviews
- Career coaching
- Resume review
Learn everything you need to ace your software engineering interviews.
Exponent is the fastest-growing tech interview prep platform. Get free interview guides, insider tips, and courses.
Create your free accountRelated Courses

Software Engineering Interview Prep Course

Technical Program Management Interview Prep Course
Related Blog Posts

What Is The Role of a Technical Program Manager?
15 Teleconferencing Tips for a Successful Remote Interview

