

The CAP theorem is an important database concept to understand in system design interviews. It’s often not explicitly asked about, but understanding the theorem helps us narrow down a type of database to use based on the problem requirements. Modern databases are usually distributed and have multiple nodes over a network. Since network failures are inevitable, it’s important to decide beforehand the behavior of nodes in a database, in the event that packets are dropped/lagged or a node becomes unresponsive.
Partition Tolerance and Theorem Definition
CAP stands for “Consistency”, “Availability”, and “Partition tolerance”. A network partition is a (temporary) network failure between nodes. Partition tolerance means being able to keep the nodes in a distributed database running even when there are network partitions. The theorem states that, in a distributed database, you can only ensure consistency or availability in the case of a network partition.
Example Scenario
To better understand the situation with network partitions, we give an example scenario.
In a multi-master architecture, data can be written to multiple nodes. Let’s pretend that there are two nodes in this example database. When a write is sent to Node A, Node A syncs the update with Node B, and any read requests sent to either of the two nodes will return the updated result.
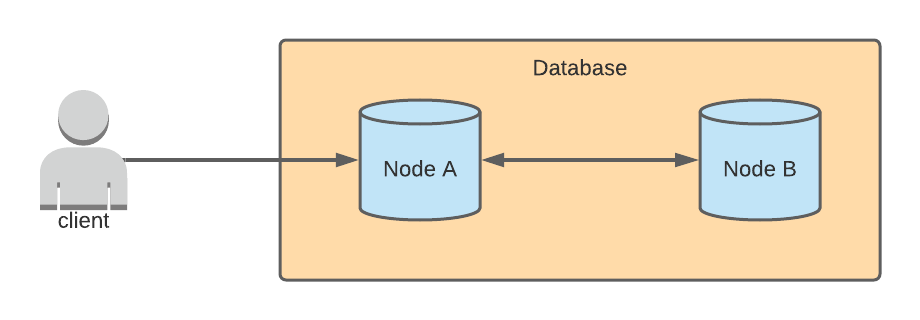
If there is a network partition between Node A and Node B, then updates cannot be synced. Node B wouldn’t know that Node A received an update, and Node A wouldn’t know if Node B received an update. The behavior of either node after receiving a write request depends on whether the database prioritizes consistency or availability.
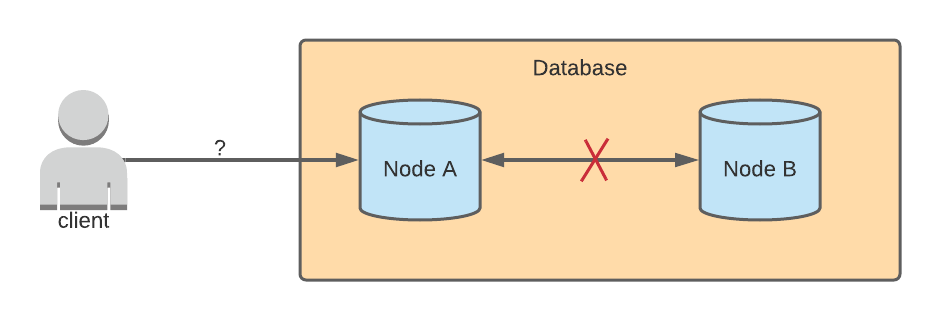
Consistency
Consistency is the property that after a write is sent to a database, all read requests sent to any node should return that updated data. In the example scenario where there is a network partition, both Node A and Node B would reject any write requests sent to them. This would ensure that the state of the data on the two nodes are the same. Or else, only Node A would have the updated data, and Node B would have stale data.

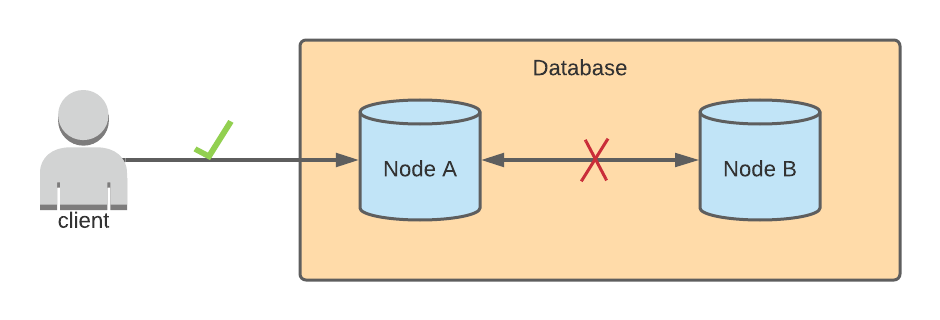
Availability
In a database that prioritizes availability, it’s OK to have inconsistent data across the nodes, where one node may contain stale data and another has the most updated data. Availability means that we prioritize nodes to successfully complete requests sent to them. Available databases also tend to have eventual consistency, which means that after some undetermined amount of time when the network partition is resolved, eventually, all nodes will sync with each other to have the same, updated data.In this case, Node A will receive the update first, and after some time, Node B will be updated as well.
When should Consistency or Availability be prioritized?
If you’re working with data that you know needs to be up-to-date, then it may be better to store it in a database that prioritizes consistency over availability. On the other hand, if it’s fine that the queried data can be slightly out-of-date, then storing it in an available database may be the better choice. This may seem kind of vague, but check out the examples at the end of this post for a better understanding.
Read Requests
Notice that only write requests were discussed above. This is because read requests don’t affect the state of the data, and don’t require re-syncing between nodes. Read requests are typically fine during network partitions for both consistent and available databases.
SQL Databases
SQL databases like MySQL, PostgreSQL, Microsoft SQL Server, Oracle, etc, usually prioritize consistency. Master-slave replication is a common distributed architecture in SQL databases, and in the event of a master becoming unavailable, the role of master would failover to one of the replica nodes. During this failover process and electing a new master node, the database cannot be written to, so that consistency is preserved.
Popular Databases that Prioritize Consistency vs. Availability

Does Consistency in CAP mean Strong Consistency?
In a strongly consistent database, if data is written and then immediately read after, it should always return the updated data. The problem is that in a distributed system, network communication doesn’t happen instantly, since nodes/servers are physically separated from each other and transferring data takes >0 time. This is why it’s not possible to have a perfectly, strongly consistent distributed database. In the real world, when we talk about databases that prioritize consistency, we usually refer to databases that are eventually consistent, with a very short, unnoticeable lag time between nodes.
I’ve heard the CAP Theorem defined differently as “Choose 2 of the 3, Consistency, Availability or Partition Tolerance”?
This definition is incorrect. You can only choose a database to prioritize consistency or availability in the case of a network partition. You can’t choose to forfeit the “P” in CAP, because network partitions happen all the time in the real world. A database that is not partition tolerant would mean that it’s unresponsive during network failures, and could not be available either.
Short Exercises
Question 1
You’re building a product listing app, similar to Amazon’s, where shoppers can browse a catalog of products and purchase them if they’re in-stock. You want to make sure that products are actually in-stock, or then you’ll have to refund shoppers for unavailable items and they get really angry. Should the distributed database you choose to store product information prioritize consistency or availability?
Answer:
Consistency. In the case of a network partition and nodes cannot sync with each other, you’d rather not allow any shoppers to purchase any products (and write to the database) than have two or more shoppers purchase the same product (write on different nodes) when there is only one item left. An available database would allow for the latter, and at least one of the shoppers would have to have their order canceled and refunded.
Question 2
You’re still building the same product listing app, but the PMs have decided, through much analysis, that it’s more cost effective to refund shoppers for unavailable items than to show that the products are out-of-stock during a network failure. Should the distributed database you choose still prioritize consistency or availability?
Answer:
Availability. Canceling and refunding the order of a shopper would be preferable to not allowing any shoppers to purchase the product at all during a network failure.
Book time with a Technical Program Manager coach
- Mock interviews
- Career coaching
- Resume review
Learn everything you need to ace your software engineering interviews.
Exponent is the fastest-growing tech interview prep platform. Get free interview guides, insider tips, and courses.
Create your free accountRelated Courses

Software Engineering Interview Prep Course

Technical Program Management Interview Prep Course
Related Blog Posts
Technical Program Manager Interview Prep (2026 Guide)

What TPM Interviewees Need to Know About Cross-Functional Partnerships

How to Answer System Design Questions like "Design Twitter."

