How to Answer System Design Questions like "Design Twitter."
Technical Program Management Anthony Pellegrino • Last updated
Anthony Pellegrino • Last updated 
Systems thinking will be a big part of your job as a software engineer, technical program manager, or engineering manager. You may focus on a few key areas, but you're expected to have a broad understanding of how components work together. The system design interview tests this ability.
The most common system design question you'll come across will ask you to design some well-known product or technology from the ground up. Whether it be Twitter, Instagram, Facebook Messenger, or even a web crawler, aspiring TPMs must prepare. These types of system design questions will generally look something like this:
Walk me through how you would design <product> that will support the following features:
Requirement 1
Requirement 2
etc
The best way to demonstrate how to answer these types of questions is with some examples.
Design Twitter

First and foremost, when answering a system design question, you should establish the bare minimum requirements for the application in question. In this case, it is Twitter. Usually, the interviewer will give you an overview of some requirements they'd require, but not always. Even so, you should always confirm the requirements before diving deeper into your design.
The requirements for Twitter would be something like the following:
- Sending tweets
- Following other users
- Tweet feed/newsfeed
- System is scalable
- Loads quickly
- System is reliable
After you establish the requirements, you can begin to outline your design of the Twitter API. That would look something like this:
We'll start by outlining important endpoints for the API design. These include:
sendTweet(message)
followUser(userID)
unfollowUser(userID)
getFeed(page)
Then, we can begin sketching out the architecture to support these features. We can start with the user who makes a request to the server. To accommodate the scalability requirement, we can put several API servers behind a load balancer to help route larger traffic volumes. Now, we need to include a database to store our tweets. We have to keep in mind that the API we design needs to be scalable. Therefore, we need to choose a database that is easy to shard and a data model that can handle a large number of reads and writes on the part of the API servers.
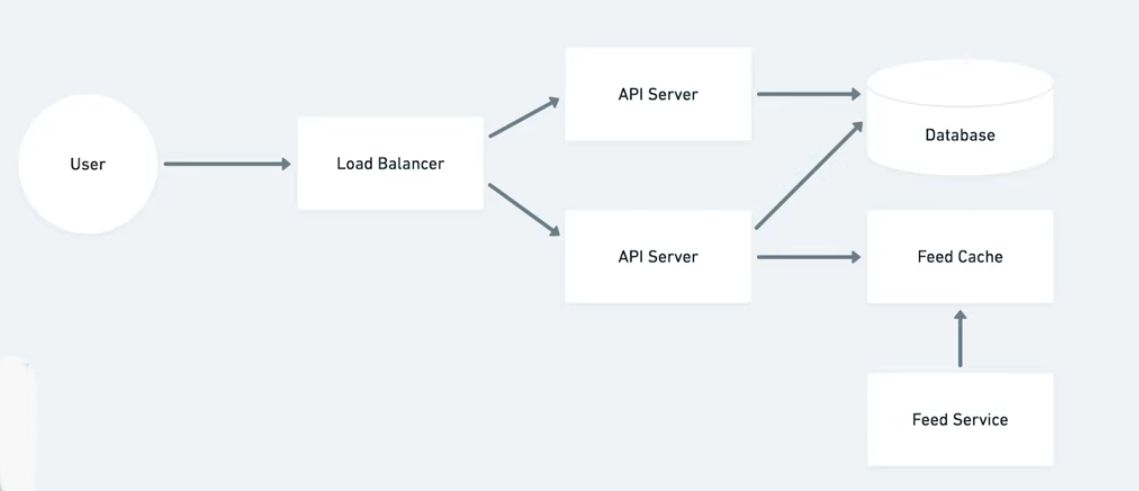
When it comes to making this application scaleable, we can have one of our API servers read from a separate cache for our newsfeed. In doing so, we should also use a feed service to refresh our feed cache regularly.
For more details, you can watch our Design Twitter video here.
Design Flickr

So we start as we did with Twitter; by listing the requirements. For Flickr, our system will need to be able to:
- View posts
- Like posts
- Comment on posts
- Create posts
- Follow other users
Now, with our design requirements staked out, we can continue onto our system architecture. We can initially deploy our application on a simple infrastructure without needing load balancing or horizontal scaling.
Next, we can focus on our user interface. For a Flickr-esque application, we'll probably need a UI with two views: one for all posts and another for posts from followed users. For the view for all posts, the newsfeed will need to be a series of posts allowing users to comment, like, or follow the user who posted. Additionally, a user could create a new post. For the other view, the newsfeed can be designed as a series of posts only from followed users. For performance's sake, it's best to paginate the posts so the system does not need to load more than a few posts at a time.
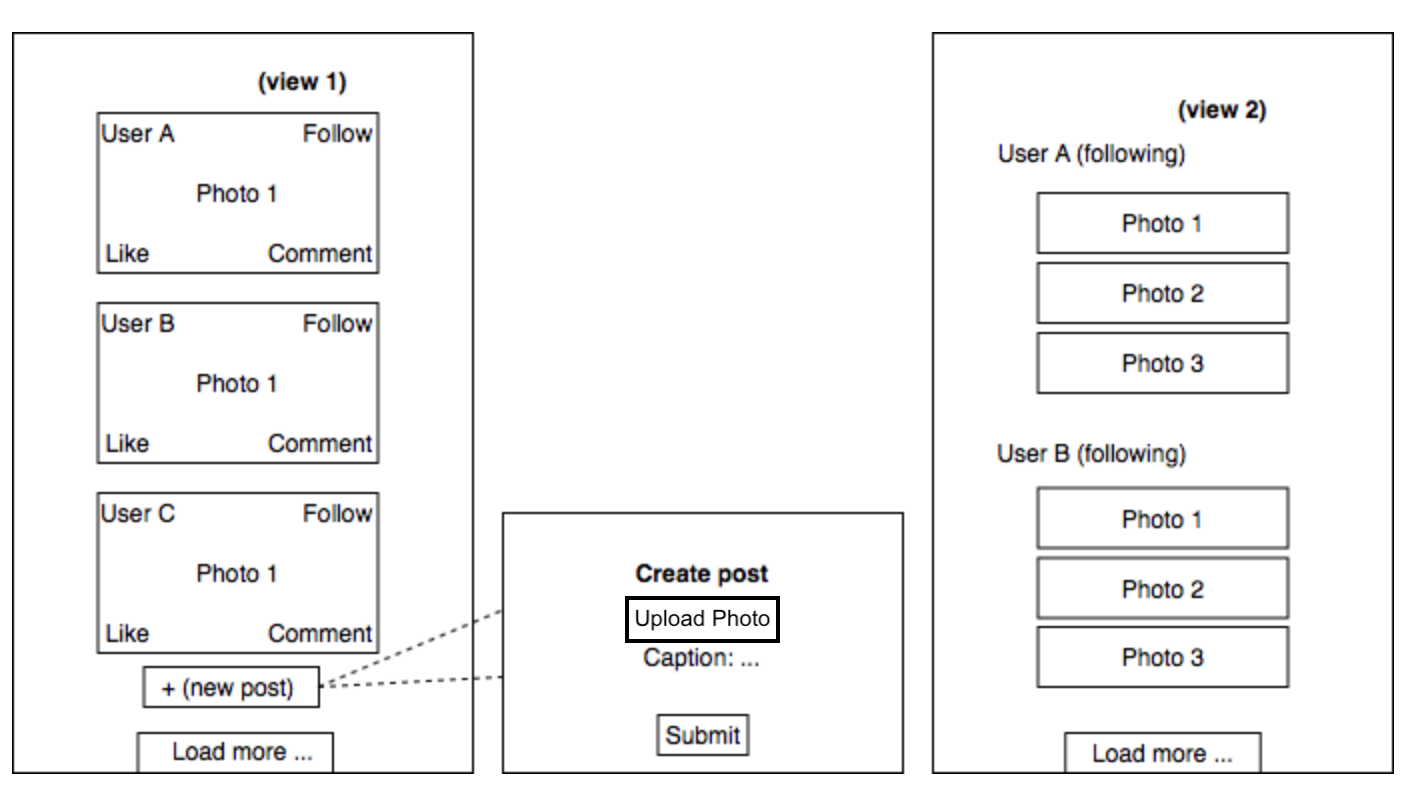
Now, we can outline the necessary API endpoints that we'll need for the app's frontend. Firstly, a GET endpoint will need to be defined to retrieve all the posts for both of our views. Another POST endpoint will support the creation of new posts with the associated attributes we'd want( photo URL and caption, for example).
When it comes to choosing our database, SQL could be the best choice for all our non-photo data. When it comes to images, our system can use an S3-esque data solution. In terms of the design of our database, we need to focus on two entities: that of the image posts and the users. These two will be our first data tables. But these aren't the only things we'll need in our database. We'll also need tables for likes, comments, and followers. So, let's take a look at what this database scheme would look like:
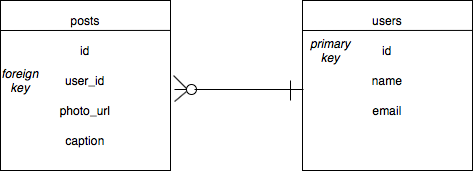
Here we can see that the user_id in our posts table is the foreign key that connects users to the various posts on the application. An individual user can have several posts, but every post only has one author.
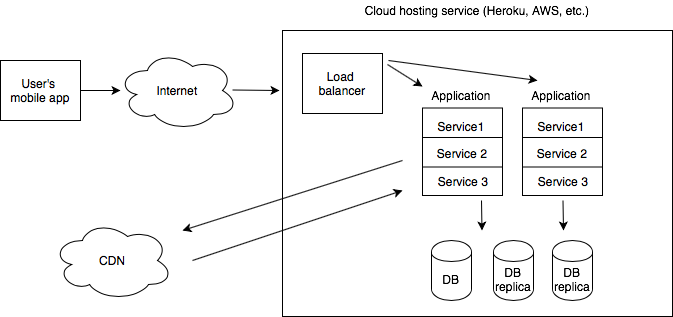
Thus far, we've outlined the structure of our Flickr application. Now, we'll need to outline the ways we can make it sturdy and reliable. In this regard, we should consider that our application, like many social media applications, is very read-heavy. This means that, as we scale the app, we'll need to optimize this to maintain reliability. Here are some strategies that can do so:
- Using load balancers to support increased traffic
- Organize the application into a series of microservices
- Optimize the application's queries
- Make use of a sturdy content delivery network
- Make use of sharding in the database stack
Design a Web Crawler
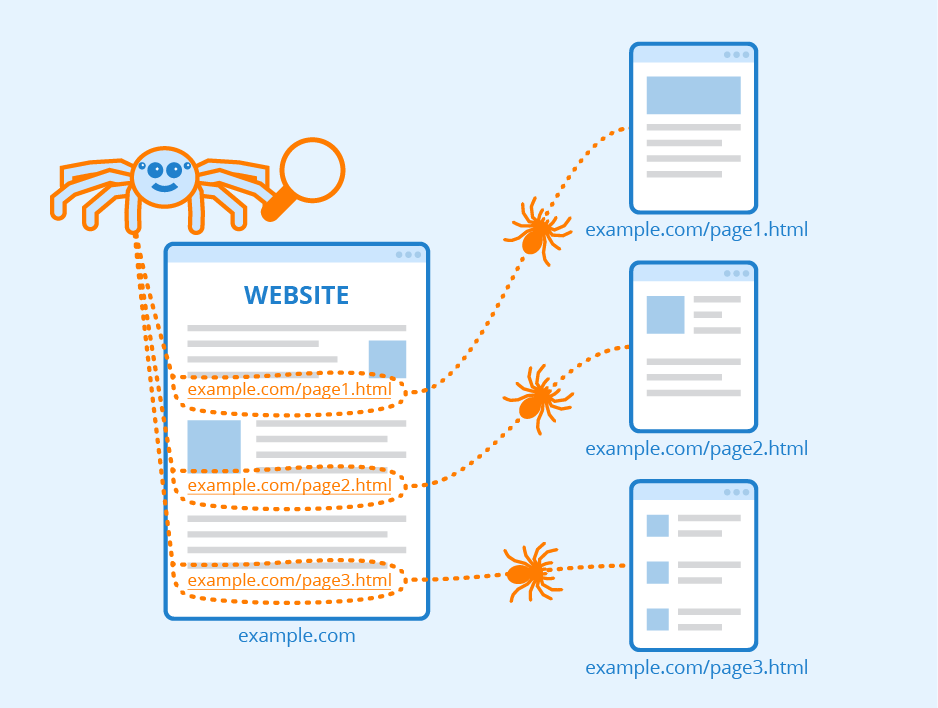
Being asked to design a web crawler is a commonly asked system design question. An interviewer asking this question also accomplishes a few things at once. First and foremost, a candidate will require a thorough understanding of the technical details of how the internet works. Not only that, they'll need a conceptual understanding, as well. This question gets at the root of both. So, how can you answer this question?
Define the Problem and Clarify the Requirements
Like any other system design question, candidates will first need to clarify and outline all the requirements of the question. Your interviewer will probably give you some general requirements, but be sure to clarify to ensure you have the full scope before you continue. When it comes to our web crawler, you can ask questions like:
- Are we prioritizing certain webpages over others while we crawl?
- What are the constraints on the data our crawler can store if any?
- What assumptions are we making about the webpages? Should we assume they all contain HTML, for example? Should our crawler account for other media types beyond this?
Outline and Implement the Crawler
Every web crawling application must be able to do the following:
- Visit websites while scanning their contents
- Find URLs from website contents
- List URLs that have yet to be crawled
- Repeat until all URLs are crawled
Now, there isn't just one way to design such an application. However, when it comes to web crawlers, there are two main approaches we can take. These are the breadth-first or depth-first approaches. For this article, let's imagine that we go with the breadth-first. This means that our crawler will be visiting web URLs as it discovers them. We can implement this approach by storing the URLs our crawler has yet to visit in a first-in-first-out data structure while initializing it in such a way as to ensure it only contains the initial URLs that are given. Since we are using a first-in-first-out data structure, our crawler will only visit the URLs in the exact order that they are added to the list of URLs to crawl.
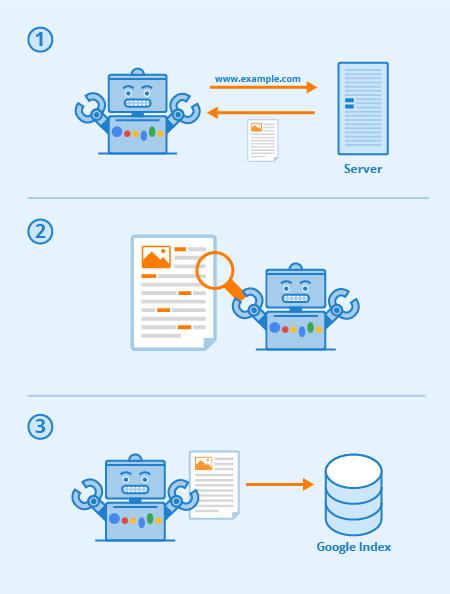
After we have our list of URLs, our crawler then needs to visit the sites and extract their contents. For a web crawler to "visit" a site, it simply makes an HTTP request to the URL while loading the page contents.
It also shouldn't be forgotten that much of the modern web contains much more than just HTML. Many sites today contain Javascript applications that make use of scripts and APIs. While you should clarify with your interviewer (in the case of this particular question) what sites your crawler is crawling, we can assume we are only focusing on the simpler HTML sites.
Once the web crawler has crawled the page and scanned its contents, it needs to extract any other links that it finds on the page. This can actually be handled rather easily thanks to many of the standard HTML libraries. After your crawler makes its list of links, they are placed on the queue to be crawled, and our crawler can repeat its process.
Data processing and storage
It should come as no surprise that to build a web crawler capable of the entire internet, you'll need access to a massive amount of storage space. For a rough estimate, let's do some quick math: If the average size of a crawled webpage is, let's say, 200 KB, and our web crawler was to store 1 million, or 10^6, pages, we'd need 2 terabytes worth of storage.
(10^6 * 200 * 10^3 = 200 * 10^9 = 2 * 10^11 bytes = 2 TB)
Now, that's conservatively speaking. Today, there are more than a billion pages on the modern web. If each of these pages was 200 KB, that would be 0.2 petabytes of data. Long story short, our crawler will need a whole lot of space. Deciding on our storage system, however, is dependent on how we plan on using our web crawler.
For instance, let's say we were building our web crawler to download and store web contents to archive offline. In this case, we'd just need to compress and store our crawled contents, and we could do so with cloud storage. However, if we were building our web crawler for searches in real-time, we may find that a distributed database would be better served for search and querying. Regardless, the amount of data necessary makes it impractical to store in memory. Instead, the memory will need to be continuously uploaded to a storage system. If not, the web crawler will run out of usable memory as it executes. This is known as an "ETL" approach, standing for "extract, transform, load".

Make Use of Parallelization
Finally, we can make use of parallelization to ensure that the web crawler is efficient and reliable. This essentially means that we design our processes to work in tandem with one another. There are a few ways to do this:
- Implement the crawler with a multi-threaded or asynchronous approach
- Run multiple instances of the crawler as different processes on a single machine
- Run multiple machines that share a job queue
You're not limited, here, to just one choice. If anything, it'd be best to make use of all three to achieve the best result.
Keys to Success

While every system design question may differ from one another, here are some general tips and keys to success:
- Before you start outlining your solution or design, be sure to define and clarify the scope. This means the who and what you are solving for. Doing so will also help you reason through the different tradeoffs along the way.
- You may have to make several decisions as you work through your solution. Be sure to talk through and outline all the tradeoffs and downsides of the options you can take. You should explain to your interviewer why the decision you make or the approach you chose is the wisest given the pros and cons.
- Always be answering the "why?" questions that inevitably arise. Always explain why you make the decisions you do while you solve the problem.
Ace the System Design Interview
System design interviews can be both exciting and nerve-wracking. If you're looking for a review of system design concepts or a chance to practice you skills, check out Exponent! Review our company-specific interview guides, interview prep courses, or sign up for coaching. You'll also get access to a dynamic community of tech insiders and like-minded job seekers - everything you need to ace the interview. So what's the hold-up? Sign up with Exponent today!
Book time with a Technical Program Manager coach
- Mock interviews
- Career coaching
- Resume review
Learn everything you need to ace your technical program management interviews.
Exponent is the fastest-growing tech interview prep platform. Get free interview guides, insider tips, and courses.
Create your free accountRelated Courses

Software Engineering Interview Prep Course

Technical Program Management Interview Prep Course
Related Blog Posts

What is System Design in Technical Program Management?

What is Program Sense in Technical Program Management?

System Design Interview Prep: SQL vs NoSQL Databases

