In this system design mock interview, we ask Hozefa to design a rate limiter. Hozefa is an engineering manager at Meta. Learn more in Strategies for Improving Availability in system design interviews.
Sneak Peek: The three most common system design questions:
- Design Instagram. Watch an answer to this question here.
- How would you build TinyURL? Watch answer here.
- Design YouTube. Watch a sample answer to this question here.
What is a rate limiter?
A rate limiter is a system that blocks a user request and only allows a certain number of requests to go through in a specified period.
Preventing these attacks helps to reduce costs for the company. They need fewer servers to manage their traffic load.
These attacks prevent users from accessing a service when it looks like they might overload a system.
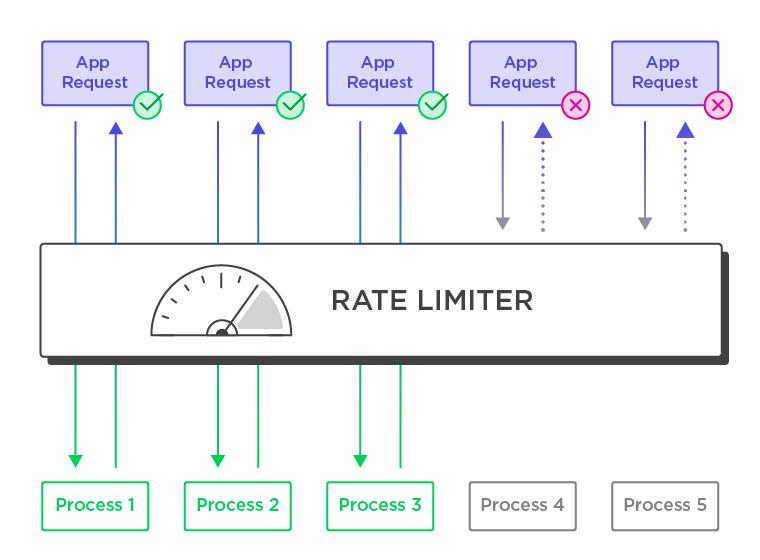
The idea is that any one particular user or set of users doesn't exponentially take up most of your computing. You use rate limiters to better manage computing power.
Prerequisites
How do you identify which users to rate limit?
You could segment users based on a unique identifier like their userID or IP address.
In this example, I'll use IP address. Why?
An IP address is always unique to a user. You can narrow down your traffic based on a set of IP addresses.
It's easy to spoof user IDs or unique internal identifiers. New user accounts can get made, etc. It's hard to identify which user IDs are valid and which ones might be spam.
Using an IP address instead, it's easier to narrow down the source of the problem.
Once I block a user, the system should notify them.
Luckily, the HTTP layer has a built-in protocol for that. We will send users a 429 response code from the server, letting them know they've been blocked.
I'll also consider some kind of logging mechanism on the server side in order do analysis on the traffic patterns in the coming weeks.
How do you rate limit?
There are many algorithms available to do rate limiting. It all depends on what we're trying to optimize for.
I'll discuss a few options.

One is the token bucket system. This is a very simple implementation where you have a bucket and every request from a user costs one token to fulfill. The bucket gets filled up at a constant fixed rate of tokens per second every time a user visits the application.
However, when no more tokens are available, requests are stopped.
You would send back a 429 error code instead of forwarding a user request to the server when the tokens are all gone.
It's a very simple implementation.
Obviously, there are downsides. If there are spikes in traffic, many users will not get the website response they want.
So you would have to keep tweaking the bucket size until you get it right to hold all those tokens.
It's not a very popular system.
Next is the fixed-window system. You're given a time window, and responses are limited to that fixed time window.
If you only allow 1 request per minute, for instance, and a user visits at 0:34, the next visitor will have to wait another 0:26 before the clock starts over again. Then, their request will be met.
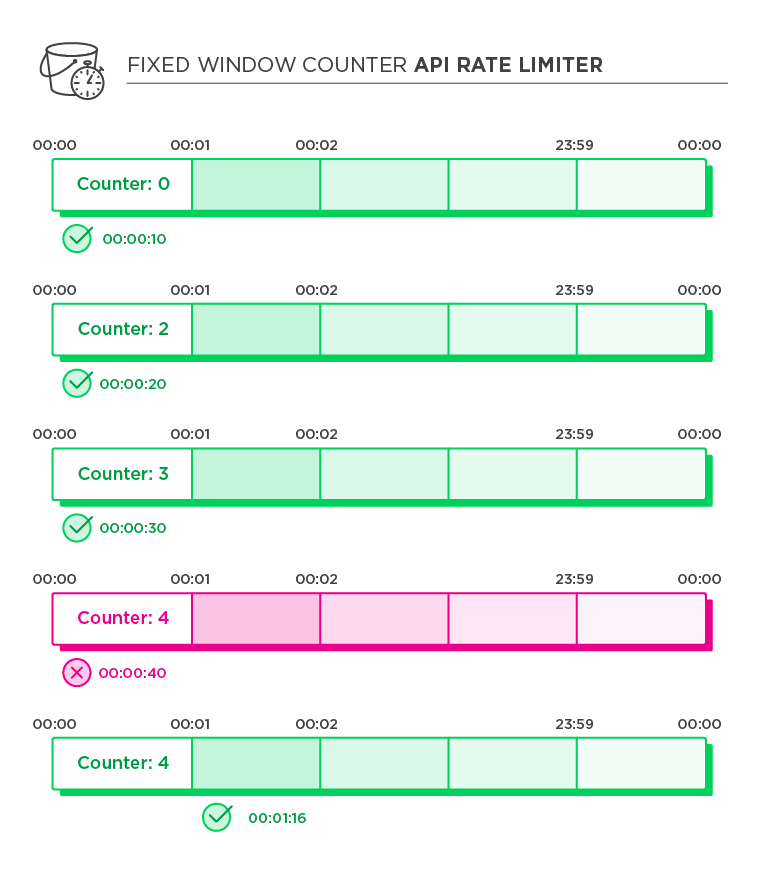
Again, the downside to this implementation is that you could have cases where requests are coming in toward the end of a time window before the next one starts. You have a big spike of requests getting processed very quickly. And then, there are large gaps before the requests get processed again.
Sliding windows in system design allow you to adjust the time frame requests that are processed to operate dynamically rather than on a fixed clock.
Systems based on traffic patterns will have you constantly tweaking your window and limit sizes to adjust to fluctuations in requests.
Design Twitter - Rate limiting
We could adapt the fixed time window algorithm to design Twitter.
I would use more of a sliding window. We aren't fixing the number of requests per second, but we keep sliding them as time passes.
If an additional request is no longer used, we can keep sliding the window with it. If there are spikes or dips in traffic, the system can accommodate them.
Interviewer: Is there a limit to how much you can slide over for each of these windows?
There are configurations that you can set when you define the rules of the system.
Things like:
- How many counters are needed within each window?
- What's the sliding scale?
At a high level, a rate limiter consists of a few components.
At the start of the interview, I mentioned that we will have a server-side implementation for this rate limiter.
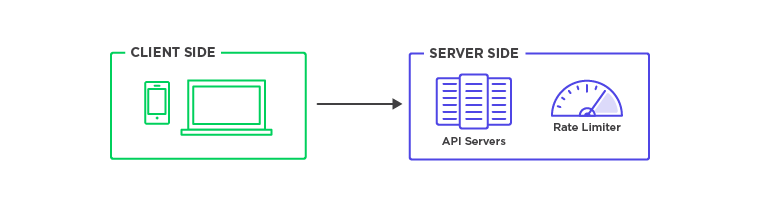
Why do we want to do this as a server-side rate limiter? On the client side, it would be easy for someone with malicious intent to forge or bypass the rate limiter.
We'll have more control over traffic flow if it happens on the server. Before our request gets processed to our API or web servers, there is a rate-limiting middleware the next component you need is behind some kind of a rule engine.
Here is where we will define what algorithm we want to use.
- What are the rules that we want to use?
- Will we use IP address, geography, or User ID to identify traffic?
The other part we need is a cache with very high throughput. As requests are coming in we need to write into the cache—which IP is getting more requests?
We can read from the cache to see if this IP has already been requested. We can then block, if needed, based on the user's IP.
And then, in parallel, we can have a logging service for future analysis.
Let's draw some of the components to make it easier to visualize.
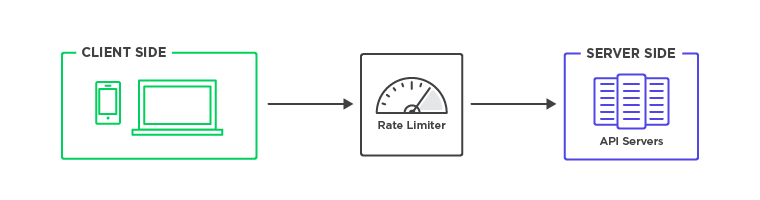
We start off with client(s). Then, we would build out our rate in our API.
On top of that, we have our rules engine.
The rate limiter will use the data from the rules engine. The API middleware is almost like an if/else statement.
If this is a success, the request returns to our API service. We'd send a 429 HTTP status code if the user request was blocked.
Additionally, we need a cache with high throughput. The reason for this cache is that the rate limiter needs to see if a particular user is being blocked. How many requests have they already consumed?
From here, you could have a system where they're doing some kind of logging mechanism. This is putting the data in long-term storage. We can analyze this data without putting additional strain on the system.
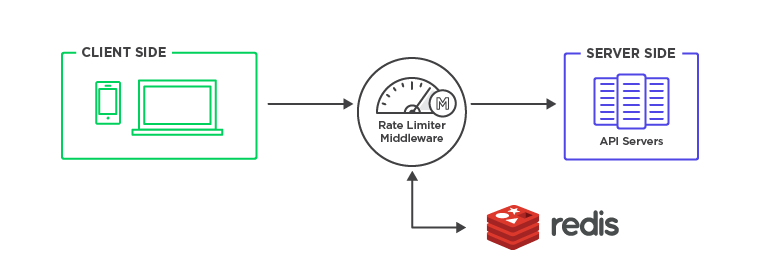
Another optimization is that the rules engine, every time a request comes to the API rate limiter, needs to check if the rules are the same or if they've changed.
You could potentially build out a cache in the middle between the rules engine and the rate limiter; the limiter will always read from the cache instead of the rules engine. This would provide faster access to the data.
To summarize, the requirements of this design are:
- It must run server side
- It will block based on IP or userID
- It will send a 429 HTTP status code if a user is blocked
- There's a logging mechanism for future use.
Interviewer: How would you modify this for a distributed environment?
This system right now it's based on a single data center environment. All the requests are coming in through the same rate limiter. They're going through the same set of web servers.
In most big systems, we have a distributed environment with multiple data centers. What we need is a load balancer.
The load balancer is managing requests across multiple servers and multiple data centers. We have multiple implementations of the rate limiter, as every data center has its own implementation of this middleware.
What remains constant or needs to scale horizontally is your cache. You need one shared cache across a distributed network.
You could look at different configurations where one read cache and one write cache. How do you sync between them?
Or have one common read/write cache shared across all the data centers.
Interviewer: Will your API rate limiters read from the same rules cache?
Yes, you could technically have multiple instances of the rules cache. In theory, the rules don't change that often. You wouldn't want to change a rule multiple times per day.
Rules generally persist over some time. So they don't need to be distributed. They can be in a few places, and the rate limiters can read from there.
Is there a situation where you'd want different rate limiters for different geographies?
I don't think so. If you do that, you'd potentially put yourself in a vulnerable position.
If people could mimic where their request is coming from, you can end up bypassing the rate limiter logic itself.
If people started using a VPN, they could hide where they're coming from. So you would want to have a consistent set of rules across the world that it's easier to manage and throttle users.
If you have different rules for Asia or the US, users will likely try to circumvent that limit independently.
Notes from the interviewer
A rate limiter, or any kind of system design interview, is a very open-ended question.
There are several ways to solve this problem.
Many big companies have different implementations to solve this problem—Google, Amazon, and Stripe.
In system design interviews, focus on the requirements and constraints. You don't need to find a perfect solution. Instead, focus on addressing common pain points and objections for the scenario you've been given.
Big companies have designed their systems in a scalable and reliable way for years. You can't replicate that in a 30-minute interview.
Best of luck with your system design interviews!
Learn everything you need to ace your system design interviews.
Exponent is the fastest-growing tech interview prep platform. Get free interview guides, insider tips, and courses.
Create your free accountRelated Blog Posts

The 10 Best System Design Books to Sharpen Your Skills

How to Whiteboard for System Design Interviews

