The machine learning system design interview asks you to design a complete ML system end to end, from framing an open-ended problem to building the data pipeline, training and evaluating a model, and serving and monitoring it in production. It usually runs 45 to 55 minutes in a conversational format, and the interviewer is watching how you reason about tradeoffs at each stage rather than whether you reach one "correct" architecture.
In 2026 the round has broadened. Many loops now include a generative AI component: designing systems built on large language models, retrieval, and agents that act on a user's behalf.
This guide covers the classic ML design process and the generative AI patterns now showing up alongside it, with a 6-step framework, the evaluation and safety topics interviewers expect, and real questions candidates have reported. For the wider loop this round sits inside, see our complete machine learning interview guide.
What Is an ML System Design Interview?
An ML system design interview evaluates whether you can turn a vague business problem into a working machine learning system and reason about the tradeoffs at each stage. You frame the ML task, design the data pipeline, choose and justify a model, define training and evaluation, and explain how the system is deployed and monitored under real constraints like latency, cost, and data drift.
It tests skills a coding round doesn't: scoping an ambiguous task as an ML problem, justifying model choices against production limits, and anticipating how a system degrades once real data arrives.
The exact shape of the ML system design interview varies by role and level. A machine learning engineer, a data scientist, and a software engineer on an ML team can all get a version of this round, and the coding bar and infrastructure depth expected scale with seniority. Treat the specifics in this guide as the common core, then confirm the emphasis with your recruiter.
ML System Design Framework
The ML system design framework is a 6-step structure that helps you budget your time, stay focused, and communicate clearly. ML design questions are hard because they ask you to combine many ML concepts into one solution under time pressure, so a consistent structure keeps your answer organized.
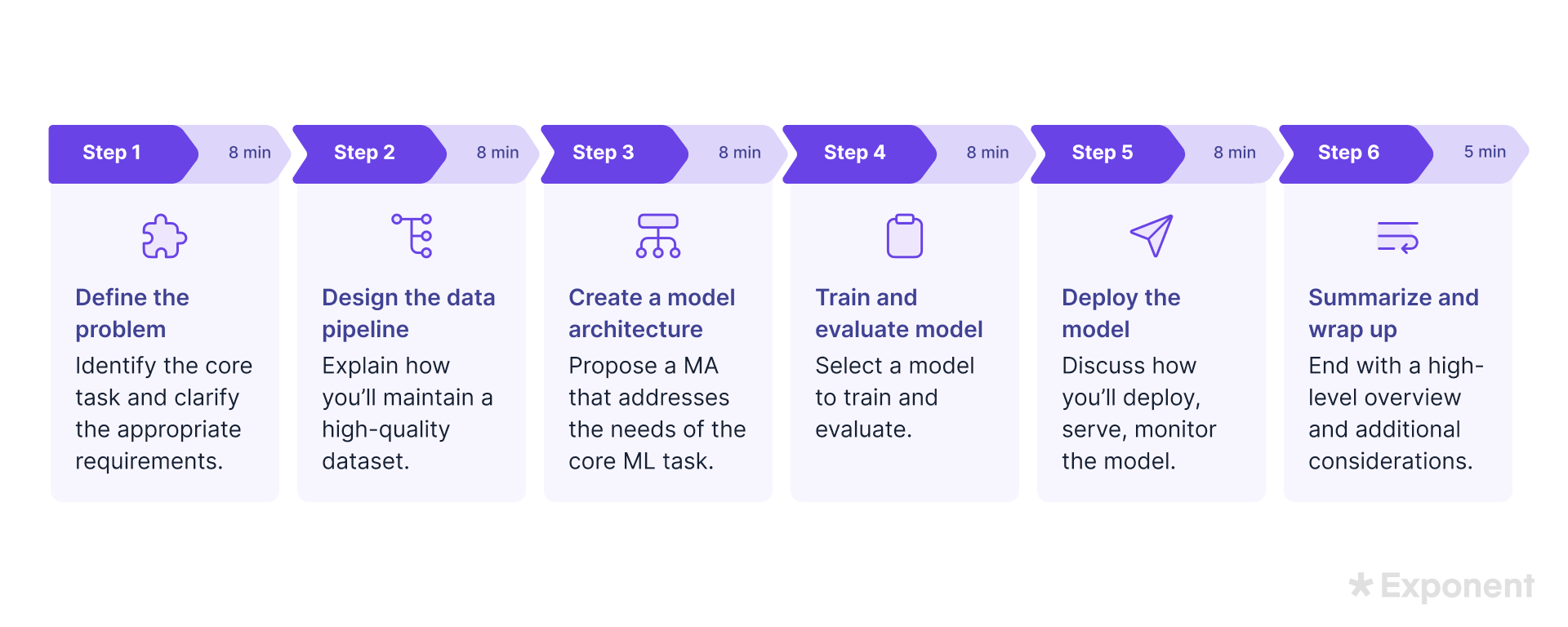
- Define the problem (~8 min): Identify the core ML task and ask clarifying questions to set requirements and tradeoffs
- Design the data processing pipeline (~8 min): Show how you'll collect and process data to keep the dataset high quality
- Create a model architecture (~8 min): Choose an architecture that fits the task from Step 1
- Train and evaluate the model (~8 min): Pick a model and explain how you'll train and evaluate it
- Deploy the model (~8 min): Decide how the model is served and monitored
- Wrap up (~5 min): Summarize the design and name what you'd address with more time
Step 1: Define the Problem
Defining the problem means setting requirements, identifying the core ML task, and aligning with the interviewer before you design anything. This step shows whether you can scope an ambiguous task and state what the system needs to do.
Start by deciding what type of learning problem you're solving, since that drives everything downstream:
- Recommendation tasks rank items by similarity using collaborative or content-based filtering on (user, item, rating) data
- Regression tasks predict a continuous value
- Classification tasks sort inputs into categories
- Generation tasks produce new outputs conditioned on an input
- Ranking tasks predict the order of a set of elements
Then set the system's goals with the interviewer: minimum accuracy and latency, expected traffic and daily active users, available data sources and their quality issues, and the compute you have for training and serving. Check each assumption before moving on.
In our Spotify example, you might frame the task as recommending artists from a user's liked songs, playlists, and artists, with success measured by engagement (a click on a recommendation counts as positive signal).
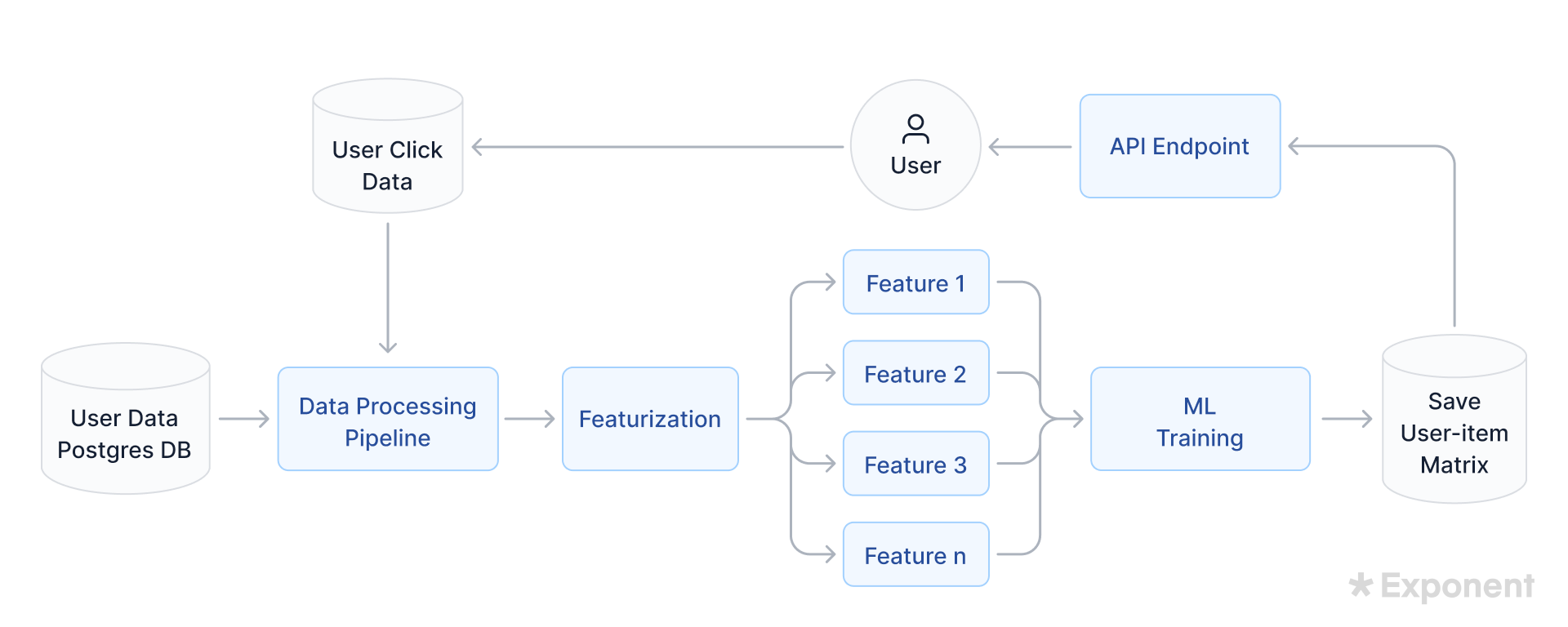
Step 2: Design the Data Processing Pipeline
The data processing pipeline is how you turn raw data into model-ready features, and designing one well signals that you treat data quality as seriously as model quality. Walk through what data you need (numbers, text, images, multimodal), how you'll collect and label it, the feature engineering and preprocessing it needs, and how you'll handle privacy and data contamination.
A common decision here is batch vs. real-time processing. Batch systems are cheaper and easier to run; real-time inference is compute-intensive but necessary for some products. Many designs train in batch and serve recent results from a cache that refreshes every few hours.
In the Spotify example, click events arrive as JSON in an object store while user metadata sits in a relational table, so you'd build an ETL pipeline that masks personally identifiable information, normalizes fields, and writes engineered features to a feature store for the model to consume.
Step 3: Create a Model Architecture
Choosing a model architecture means selecting and justifying a model once you have your data. Weigh the type of learning problem, the use case (does it need frequent retraining or personalization?), simplicity (what's the simplest model that's accurate enough?), and practical constraints around safety, storage, and latency.
Start simple. A two-tower architecture or a logistic regression baseline is often the right opening move, and you can add capacity once the interviewer signals where they want depth. Reaching for a state-of-the-art model by default is a common mistake: those models cost more to train and serve, and they're usually benchmarked on academic data that doesn't match a production setting.
In the Spotify example, a collaborative-filtering baseline that scores user and item vectors and compares them in a user-item matrix is enough to start, with room to add a neural model later.
Step 4: Train and Evaluate the Model
Training and evaluating the model means deciding on an optimizer, the metrics you'll monitor, and your hyperparameter strategy. Your plan may shift with hardware availability, parallel training jobs, and how you distribute data and parameters across devices, and some tasks let you fine-tune a pretrained model instead of training from scratch.
For evaluation, present a plan that fits where the model runs and how a wrong prediction hurts users. Cover accuracy (F1, precision, recall), bias and group fairness, calibration, stability under small input changes, and comparison against simple baselines. Be ready to discuss tradeoffs between metrics, such as how precision@k compares to ndcg@k for a ranking task. Showing you understand these tradeoffs signals that you can tune a model for its real purpose rather than its benchmark score.
Step 5: Deploy the Model
Deploying the model covers three things: deployment timing (A/B tests, canary deployment, feature flags, or shadow deployment), model serving (hardware choice, model compilation, traffic patterns), and monitoring. State a plan for each.
Post-production monitoring matters more for ML systems than for most software, because incoming data shifts constantly and degrades performance. Decide on your ground-truth dataset, your indicators for performance regression, and your troubleshooting tools.
In the Spotify example, you might serve batch recommendations from a cache, run an A/B test against current engagement, and monitor for model, data, and feature drift over time.
Step 6: Wrap Up the Design
Wrapping up means reviewing the problem scope and your pipeline, then naming the main bottlenecks and tradeoffs in the last few minutes. Explain why those tradeoffs were acceptable, how you'd scale for more data or requests, and how you'd adjust the model for distribution shifts.
Ending with a short recap plus the considerations you'd tackle with more time shows you understand the system end to end, beyond the one part you designed in detail.
Generative AI System Design in 2026
Generative AI system design is now part of the ML system design round, and it's the biggest change to the interview in 2026. Two shifts define it:
- Generative AI design has entered the standard question pool
- Operational depth (cost, monitoring, failure modes) is scored explicitly instead of treated as a bonus
A year ago, "design a system that serves an LLM" was reserved for specialized roles; it now appears in general ML and software loops, and at AI-first companies entire rounds can center on it. Use the same 6-step framework, but expect failure modes and tradeoffs.
Retrieval-augmented generation (RAG)
RAG grounds an LLM's answers in external data by retrieving relevant documents and adding them to the model's context at query time. Design the full path: how documents are chunked, how chunks are embedded, which vector database stores them, how you retrieve and rank candidates, and how retrieved context is assembled into the prompt.
The tradeoffs interviewers look for include chunk size (small chunks retrieve precisely but lose context; large chunks do the reverse), embedding model choice, retrieval quality versus latency, and keeping the index fresh as source data changes.
LLM serving: latency and cost
Serving an LLM forces tradeoffs smaller models don't. Discuss batch versus real-time inference, KV caching to avoid recomputing attention over the prompt, GPU allocation, and when a smaller or distilled model is good enough.
Cost is a first-class design constraint here, so knowing when to cache vs. recompute, when to batch, and when a cheaper model suffices signals production judgment. For larger systems, be ready to talk about distributed training, model parallelism versus data parallelism, and how hardware constraints shape the design.
Context, memory, and reliability
LLM systems manage a finite context window and decide what to keep across a conversation. Be ready to discuss handling long context, storing and retrieving chat history, and keeping outputs consistent in production.
When to use an LLM versus plain ML
A recurring signal in this round is whether you pick an LLM for the right reasons. Defaulting to a large model when a logistic regression or a retrieval system would be cheaper and more reliable is a red flag. Naming that tradeoff before you're asked is a strong move.
Evaluation beyond accuracy
Generative systems often have no single correct output, so bring metrics that fit the task:
| Metric | What it measures | What it misses |
|---|---|---|
| BLEU | N-gram overlap with reference text (common for translation) | Meaning; rewards surface overlap |
| ROUGE | Overlap for summarization, recall-oriented | Correctness; favors surface similarity |
| Perplexity | How well a model predicts a sample | Only an indirect signal of user-facing quality |
| Faithfulness / hallucination rate | Whether outputs are grounded in the source | Fluency alone won't catch it; often the key metric for RAG |
Safety and guardrails
Interviewers increasingly expect a safety plan: input and output filtering, prompt-injection defenses, rate limiting and per-user identification to prevent abuse, and human-in-the-loop review for high-risk actions. Build safety in as its own design dimension from the start, especially for systems that can act on a user's behalf.
Agentic patterns
Agentic design asks you to build a system where an LLM plans and takes actions through tools. Discuss tool use and function calling (how the model selects and validates tools), multi-agent orchestration (when to split work across specialized agents and how they coordinate), and observability (how you trace, debug, and measure an agent in production).
Observability is the piece candidates most often skip: an agent that works in a demo but can't be traced or rolled back in production won't pass.
Common ML System Design Interview Mistakes
The most common mistakes in the ML system design round are scoping errors, over-engineering, and skipping evaluation. Here are some common interview mistakes and how to avoid them:
- Rushing to a solution: Analyze the task before you design. Clarify requirements, context, and data scale, then check with the interviewer on what to prioritize once you have a baseline.
- Looking for one "right" answer: There usually isn't one, so justify your design against the alternatives instead of reciting a memorized solution that falls apart under follow-up questions.
- Defaulting to state-of-the-art models: Start with the simplest model that meets the requirements, since SotA models are often less efficient and benchmarked on academic data rather than a production setting.
- Overcomplicating the model: Build a low-capacity v1 that works on clean data first, then expand it for messy data and edge cases.
- Skipping evaluation and monitoring: Budget time to explain how you'll validate the model at launch, both quantitatively and qualitatively, and how you'll monitor it for drift once it's live.
ML System Design Interview Questions
These are real machine learning system design questions that hiring managers and candidates have reported at FAANG and other top companies, grouped by task type:
Recommendation and ranking
- Design a product recommendation system. (Meta, Pinterest)
- Design Netflix's "Top Picks" feature. (Meta)
- Design Instagram's Explore page. (Meta)
- Recommend similar artists on Spotify. (Spotify)
- Design an evaluation framework for ads ranking. (Meta)
- Design a personalized news ranking system. (Meta)
- Design a product ranking system for Amazon shopping.
Natural language processing
- Detect the language of a text input. (Meta)
- Design a customer support chatbot.
- Design a fake news detection system. (Meta)
- Design a podcast search engine.
Content moderation and filtering
- Design an automated comment moderation system. (Meta)
- Design a spam detection system on Pinterest. (Pinterest)
- Design a fraud-detection system for Stripe.
Computer vision
- Design visual search for Pinterest.
- Design blurring for Google Street View.
- Design a shape-detection system.
Monitoring and infrastructure
- Design an ML monitoring system for drift, performance, and outliers.
- Design a monitoring system for TikTok. (TikTok)
- Design the feature pipeline, latency budget, and A/B test for a ranking model.
Generative AI and LLM
- Design a high-level system for an LLM responding to a user query.
- Design a customer-support chatbot on top of a third-party LLM platform.
- Design safeguards for an AI system that can take actions on a user's behalf.
- Build a customer support agent and define its metrics and observability.
How the ML System Design Round Fits the ML Loop
The ML system design round is one stage in a larger interview loop that also includes ML coding, ML concepts, and behavioral rounds.
This guide covers the system design stage only. For the full sequence and how the stages connect, see our complete machine learning interview guide.
Because ML system design is a specialization of general system design, the system design interview guide is worth reading for the distributed-systems fundamentals (APIs, storage, caching, scale) that carry over into the ML version.
How to Prepare for the ML System Design Interview
The most effective prep for your ML system design interview combines a repeatable framework with realistic spoken practice and current knowledge of LLM and infrastructure topics. Here are a few things that are working for candidates now:
- Confirm what "coding" and "design" mean for your loop before you prepare. Ask your recruiter whether the round is modeling-heavy or infrastructure-heavy, because the preparation differs, and expect the coding bar to reach full software-engineer level at some companies even when the title says machine learning.
- Bring up the topics of scale, latency, and monitoring yourself. Don't wait to be asked about cost tradeoffs, failure modes, and drift monitoring.
- For generative AI prompts, reason about when a simpler ML approach is cheaper and more reliable instead of defaulting to a large model.
- Practice out loud. Many candidates run this round with no diagramming tool, so rehearse reasoning through a design in real time with a peer mock interview or an ML interview coach.
- Study the production-ML and LLM fundamentals in our machine learning interview prep course.
FAQs about the ML System Design Interview
Do I need to know LLMs and generative AI for ML system design interviews in 2026?
Knowing LLMs and generative AI is necessary for ML system design interviews at AI-first companies and roles involving AI features, and increasingly useful elsewhere. You should understand RAG, LLM serving tradeoffs, context-window management, and basic evaluation and safety, without needing research-level depth. At traditional tech companies, generative AI questions are becoming more common but aren't yet universal, so recommendation, ranking, and computer-vision design still fill many loops.
How long is an ML system design interview?
An ML system design interview typically runs 45 to 55 minutes. Budgeting time across the 6-step framework, roughly 8 minutes per step with 5 minutes to wrap up, keeps you from over-investing in one stage.
What's the difference between ML system design and general system design?
The difference between ML system design and general system design is the model lifecycle. General system design focuses on distributed systems: APIs, databases, caching, and scale. ML system design adds framing the ML task, building a data pipeline, training and evaluating a model, and monitoring it for drift in production. In 2026 the two are converging as LLM design appears in both.
What is the most effective way to prepare for an ML system design interview?
The most effective preparation is repeated spoken practice against real prompts with another person. Reading about architectures helps but isn't enough, because the interview is a live conversation under time pressure. Running timed mock interviews until the 6-step framework is automatic is the fastest way to improve.
What do interviewers look for in an ML system design round?
Interviewers look for structured reasoning and clear tradeoffs rather than one correct architecture. A strong candidate scopes the problem, starts simple, justifies each choice against latency, cost, and data constraints, and raises monitoring and failure modes without being prompted. Incorporating the interviewer's feedback during the round matters as much as the final design.
Book time with a Machine Learning Engineer coach
- Mock interviews
- Career coaching
- Resume review
Learn everything you need to ace your system design interviews.
Exponent is the fastest-growing tech interview prep platform. Get free interview guides, insider tips, and courses.
Create your free accountRelated Courses

Machine Learning Engineer Interview Prep Course

Related Blog Posts
Complete Guide to Machine Learning Engineering Interviews

How to Become a Machine Learning Engineer

