Machine Learning Interview Questions
Review this list of 106 Machine Learning interview questions and answers verified by hiring managers and candidates.Hot
New
 Asked at Snap • Machine Learning EngineerMachine Learning+2 moreMachine Learning EngineerMachine Learning+2 more
Asked at Snap • Machine Learning EngineerMachine Learning+2 moreMachine Learning EngineerMachine Learning+2 more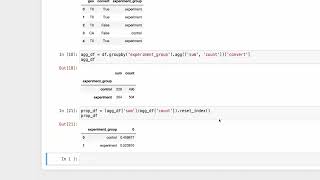 Machine LearningCoding
Machine LearningCoding Machine LearningConcept
Machine LearningConcept- Asked at Snap • Machine Learning EngineerMachine Learning+3 moreMachine Learning EngineerMachine Learning+3 more
 Asked at Samsung • Machine Learning EngineerMachine Learning+1 moreMachine Learning EngineerMachine Learning+1 more
Asked at Samsung • Machine Learning EngineerMachine Learning+1 moreMachine Learning EngineerMachine Learning+1 more Machine LearningConcept
Machine LearningConcept Asked at Anthropic • Machine Learning EngineerMachine Learning+1 moreMachine Learning EngineerMachine Learning+1 more
Asked at Anthropic • Machine Learning EngineerMachine Learning+1 moreMachine Learning EngineerMachine Learning+1 more Asked at Microsoft • Product ManagerMachine Learning+1 moreProduct ManagerMachine Learning+1 more
Asked at Microsoft • Product ManagerMachine Learning+1 moreProduct ManagerMachine Learning+1 more Machine LearningConcept
Machine LearningConcept Asked at Perplexity AI • Machine Learning EngineerMachine Learning+2 moreMachine Learning EngineerMachine Learning+2 more
Asked at Perplexity AI • Machine Learning EngineerMachine Learning+2 moreMachine Learning EngineerMachine Learning+2 more Machine LearningSystem Design
Machine LearningSystem Design- Product ManagerMachine Learning+1 more
 Machine LearningConcept
Machine LearningConcept- Data ScientistMachine Learning
 Asked at Capital One, Google, Netflix + 1 more • Machine Learning EngineerMachine LearningMachine Learning EngineerMachine Learning
Asked at Capital One, Google, Netflix + 1 more • Machine Learning EngineerMachine LearningMachine Learning EngineerMachine Learning Machine LearningConcept
Machine LearningConcept
 Asked at
Asked at 🧠 Want an expert answer to a question? Saving questions lets us know what content to make next.

 Asked at
Asked at  Asked at
Asked at  Asked at
Asked at  Asked at
Asked at Showing 61-80 of 106


