

Problem Background
When a client sends a request to an external server, that request often has to hop through many different routers before it can finally reach its destination (and then the response has to hop through many routers back). The number of these hops typically increases with the geographic distance between the client and the server, as well as the latency of the request. If a company hosting a website on a server, in an AWS datacenter in California (us-west-1), it may take ~100 ms to load for users in the US, but take 3-4 seconds to load for users in China. The good thing is that there are strategies to minimize this request latency for geographically far away users, and we should think about them when designing/building systems on a global scale.
What are CDNs?
CDNs (Content Distribution/Delivery Networks) are a modern and popular solution for minimizing request latency when fetching static assets from a server. An ideal CDN is composed of a group of servers that are spread out globally, such that no matter how far away a user is from your server (also called an origin server), they’ll always be close to a CDN server. Then, instead of having to fetch static assets (images, videos, HTML/CSS/Javascript) from the origin server, users can fetch cached copies of these files from the CDN more quickly.
Note: Static assets can be pretty large in size (think of an HD wallpaper image), so by fetching that file from a nearby CDN server, we actually end up saving a lot of network bandwidth too.
Popular CDNs
Cloud providers typically offer their own CDN solutions, since it’s so popular and easy to integrate with their other service offerings. Some popular CDNs include Cloudflare CDN, AWS Cloudfront, GCP Cloud CDN, Azure CDN, and Oracle CDN.
How do CDNs Work?
Like mentioned above, a CDN can be thought of as a globally distributed group of servers that cache static assets for your origin server. Every CDN server has its own local cache and they should all be in sync. There are two primary ways for a CDN cache to be populated, which creates the distinction between Push and Pull CDNs. In a Push CDN, it’s the responsibility of the engineers to push new/updated files to the CDN, which would then propagate them to all of the CDN server caches. In a Pull CDN, the server cache is lazily updated: when a user sends a static asset request to the CDN server and it doesn’t have it, it’ll fetch the asset from the origin server, populate its cache with the asset, and then send the asset to the user.
Push CDN
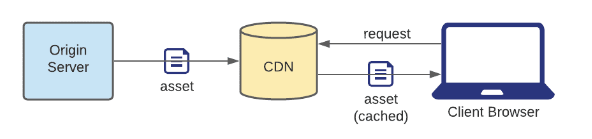
The origin server sends the asset to the CDN, which stores it in its cache. The CDN never makes any requests to the origin server.
Pull CDN
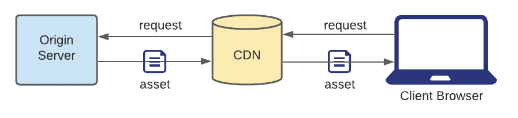
If the CDN doesn’t have the static asset in its cache, then it forwards the request to the origin server and then caches the new asset.
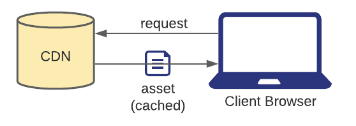
If the CDN has the asset in its cache, it returns the cached asset.
There are advantages and disadvantages to both approaches. In a Push CDN, it’s more engineering work for the developers to make sure that CDN assets are up to date. Whenever an asset is updated/created, developers have to make sure to push it to the CDN, otherwise the client won’t be able to fetch it. On the other hand, Pull CDNs require less maintenance, since the CDN will automatically fetch assets from the origin server that are not in its cache. The downside of Pull CDNs is that if they already have your asset cached, they won’t know if you decide to update it or not, and to fetch this updated asset. So for some period of time, a Pull CDN’s cache will become stale after assets are updated on the origin server. Another downside is that the first request to a Pull CDN will always take a while since it has to make a trip to the origin server.
Even with its disadvantages, Pull CDNs are still a lot more popular than Push CDNs, because they are much easier to maintain. There are also several ways to reduce the time that a static asset is stale for. Pull CDNs usually attach a timestamp to an asset when cached, and typically only cache the asset for up to 24 hours by default. If a user makes a request for an asset that’s expired in the CDN cache, the CDN will re-fetch the asset from the origin server, and get an updated asset if there is one. Pull CDNs also usually support Cache-Control response headers, which offers more flexibility with regards to caching policy, so that cached assets can be re-fetched every five minutes, whenever there’s a new release version, etc. Another solution is “cache busting”, where you cache assets with a hash or etag that is unique compared to previous asset versions.

When not to use CDNs?
CDNs are generally a good service to add your system for reducing request latency (note, this is only for static files and not most API requests). However, there are some situations where you do not want to use CDNs. If your service’s target users are in a specific region, then there won’t be any benefit of using a CDN, as you can just host your origin servers there instead. CDNs are also not a good idea if the assets being served are dynamic and sensitive. You don’t want to serve stale data for sensitive situations, such as when working with financial/government services.
Exercise
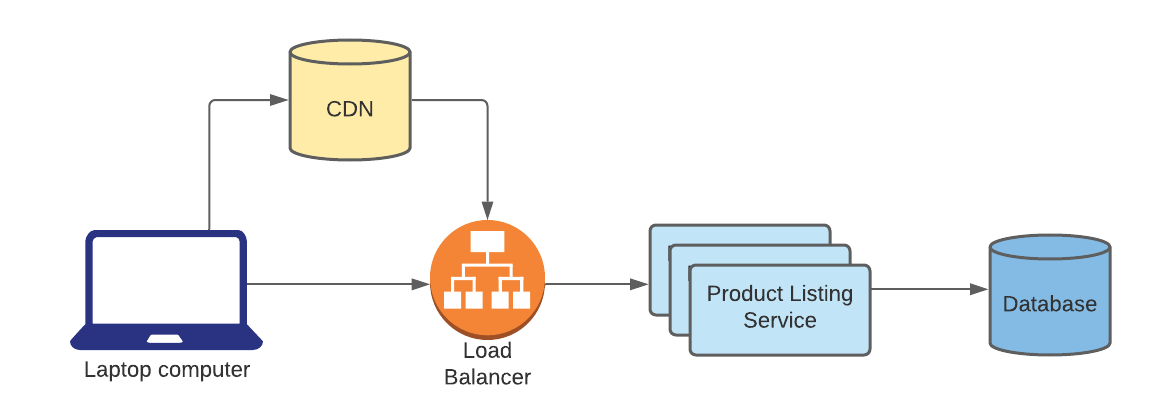
You’re building Amazon’s product listing service, which serves a collection of product metadata and images to online shoppers’ browsers. Where would a CDN fit in the following design?
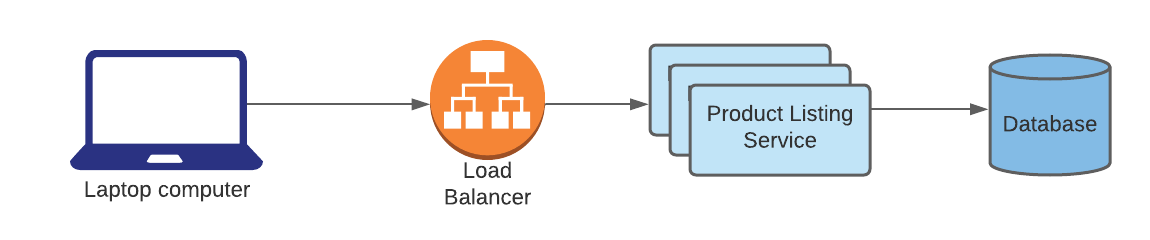
Answer:
Book time with a Technical Program Manager coach
- Mock interviews
- Career coaching
- Resume review
Learn everything you need to ace your software engineering interviews.
Exponent is the fastest-growing tech interview prep platform. Get free interview guides, insider tips, and courses.
Create your free accountRelated Courses

Software Engineering Interview Prep Course

Technical Program Management Interview Prep Course
Related Blog Posts

System Design Interview Prep: CAP Theorem
Technical Program Manager Interview Prep (2026 Guide)

What TPM Interviewees Need to Know About Cross-Functional Partnerships


{kind=link}
{kind=link}