
To help you prepare for machine learning interviews, we've compiled a list of real deep learning interview questions.
Each question is accompanied by a sample answer and an explanation of the core deep learning concepts involved.
Sneak peek:
- Watch Meta MLE answer, "Design Instagram ranking model."
- Watch Amazon MLE answer, "Describe linear regression."
- Watch Snap MLE answer, "Implement k-means clustering."
This guide was written and compiled by Derrick Mwiti, a senior data scientist and course instructor. Satyajit Gupte, an interview coach and senior machine learning engineer, reviewed it.
Deep Learning Fundamentals
Neural networks learn by iteratively adjusting their internal parameters to minimize errors, allowing them to make increasingly accurate predictions over time.
1. How do neural networks learn from data?
Neural networks learn by comparing their predictions to the actual values and adjusting the weights accordingly. The goal is to find the weights that minimize the error, known as the loss or cost function.
Selecting a loss function depends on the specific task: classification problems use classification loss functions, while regression problems use regression loss functions.
As the network continues to learn, the loss function should decrease.
2. Explain how epoch, batch, and iteration are different.
An epoch refers to one complete pass through the entire dataset. A batch is a subset of the dataset created because processing the dataset as a whole at once is impractical.
An iteration is a single update of the model’s weights.
For example, if you have 10,000 images and a batch size of 200, each epoch will consist of 50 iterations as the model processes the entire dataset in portions.
3. Explain gradient descent.
Gradient descent is a method used to minimize errors during neural network training.
It works by adjusting the model’s parameters to reduce the cost function, which measures the error.
The goal is to find the point where the error is minimized, known as the local minimum. This can be visualized as descending a slope to reach the lowest point, the global minimum. The process involves calculating the slope at a specific point on the "hill" through differentiation.
Training and Optimization
4. What is batch normalization?
Batch normalization is a technique for improving neural network training by normalizing the inputs. It ensures that the mean output is close to 0 and the standard deviation is close to 1.
During training, batch normalization normalizes the input using the mean and standard deviation of the current batch.
When making predictions, it uses the moving average of the mean and standard deviation computed during training. This method is especially effective in deep neural networks, as it helps accelerate the training process.
The batch normalization layer also has learnable parameters to scale and shift the input after normalization.
5. What is the difference between batch, mini-batch, and stochastic gradient descent?
- Batch Gradient Descent computes the gradient of the cost function using the entire dataset. While this method is accurate, it is also slow because the gradient must be calculated across the entire dataset before each update.
- Stochastic Gradient Descent (SGD) computes the gradient of the cost function using a single training example in each iteration. This makes it faster but introduces more variability in the updates.
- Mini-Batch Gradient Descent strikes a balance between the two by using a small subset (mini-batch) of the training data to compute the gradient. It combines the speed of SGD with the stability of Batch Gradient Descent.
6. Explain loss and activation functions.
An activation function in a neural network determines the final output of a model.
For instance, in a regression problem, the output should be a continuous value that predicts the quantity in question.
In contrast, for classification problems, the output is typically a probability that indicates the likelihood of each category.
For this reason, sigmoid or softmax activation functions are commonly used in classification tasks, as they constrain the output to a range between 0 and 1.
The neural network learns by comparing its predictions to the true values and adjusting the weights accordingly. The goal is to find the weights that minimize the error, measured by the loss or cost function.
The choice of a loss function depends on the specific problem. For example, classification tasks often use binary cross-entropy, while regression tasks typically use mean squared error.
7. What are vanishing and exploding gradients?
- Vanishing Gradients occur when the gradients become too small, making it difficult for the model to learn effectively. This typically happens when gradients are multiplied by weights close to zero or when using inappropriate activation functions. The result is slow learning and difficulty in training deep networks.
- Exploding Gradients are the opposite, where gradients become excessively large. This leads to large updates to the network’s weights, causing instability and preventing the network from learning properly.
8. How are weights initialized in neural networks?
Weights and biases in neural networks are typically randomly initialized when data is passed through the network. The initialization method can significantly affect the model’s ability to converge.
Common initialization methods include:
- Initializing with ones.
- Initializing with zeros.
- Using a uniform distribution.
- Applying a normal distribution.
The weights of a neural network are usually initialized by drawing from a normal distribution with zero mean and variance, which is 2/n, where n = number of neurons in the layer.
9. What is overfitting? How can it be avoided?
Overfitting occurs when a model performs exceptionally well on training data but fails to generalize to unseen data. This means the model achieves high accuracy on the training set but poor accuracy on new data, indicating its inability to generalize.
To prevent overfitting, several approaches can be used, including:
- Data augmentation: Enhancing the training data with variations to improve generalization.
- Regularization: Applying L1, L2 regularization, or dropout to penalize overly complex models.
- Data splitting: Dividing the dataset into training, validation, and test sets to monitor and adjust the model's performance.
- Early stopping: Halting training when performance on a validation set degrades.
10. How do you set batch size? Does batch size affect other hyperparameter settings?
To set the batch size:
- Start with a small batch size (e.g., 32) and increase it gradually, ensuring it doesn't exceed GPU memory limits.
- Tune the batch size for optimal performance.
Yes, batch size affects other hyperparameters:
- Large batch sizes allow for a higher learning rate because they provide more stable gradient updates.
- Small batch sizes require a lower learning rate to avoid noisy updates and instability.
- Larger batch sizes may also require fewer training epochs, as more data is processed per update.
A good rule of thumb is to use the largest possible batch size that fits on the GPU memory. Increasing the batch size speeds up training and usually means more stable weight updates. Batch size affects other hyper-parameters like learning rate and momentum. In practice, we first set the batch size before doing any hyperparameter tuning because the optimal hyperparameters depend on the chosen batch size.
11. How do you prioritize hyperparameter tuning? What are the most important parameters? How much of your budget do you allocate for tuning?
Hyperparameter tuning is critical for optimizing model performance. The most important parameters to prioritize in deep learning are:
- Learning rate: The most crucial hyperparameter, directly impacting convergence and stability.
- Optimizer type: Different optimizers can lead to varying convergence speeds and accuracies.
- Number of epochs: Determines how long the model trains and impacts overfitting/underfitting.
The tuning budget depends on your performance goals and available resources.
For example, if your goal is to achieve 90% accuracy, you can continue tuning until this threshold is reached. However, tuning must also be balanced with the project’s financial budget and deadlines.
12. How do you diagnose and improve training throughput?
Training throughput can be diagnosed using tools like TensorBoard or PyTorch Profiler to monitor metrics such as epoch duration, inference time, and GPU utilization.
To improve throughput:
- Optimize the data pipeline: Use prefetching to ensure the GPU remains active and doesn't wait for data.
- Leverage GPU-accelerated libraries: Use libraries that support GPU-accelerated data augmentation to speed up the pipeline.
- Increase batch size: This can improve throughput but will require more memory.
- Simplify network architecture: Simpler models train faster and can improve throughput.
- Use mixed precision: This technique allows for lower precision, improving training speed while maintaining accuracy.
- Use distributed training: Leveraging multiple GPUs can significantly improve training speed.
13. What do you do when training is unstable?
Unstable training is characterized by erratic fluctuations in loss and accuracy. Here are some steps to stabilize training:
- Adjust the learning rate: A high learning rate can cause the model to overshoot optimal weights. Start with a lower learning rate or use a learning rate schedule to adjust it automatically over time.
- Modify the batch size: Small batch sizes can introduce noise into gradient estimates, leading to instability. Larger batch sizes provide more stable estimates but require more memory. A good approach is to start with a batch size of 32 and gradually increase it.
- Change the neural network architecture: If the network is too complex, it may overfit; if it's too simple, it may underfit. Begin with a simple architecture and increase complexity as needed.
- Apply regularization: Techniques like dropout, L1/L2 regularization, and early stopping help create a more stable network.
- Shuffle the data: Ensure data is shuffled so the model doesn't learn patterns based on the order of the data.
- Use gradient clipping: This can prevent the exploding gradient problem, and activation functions like ReLU can help avoid vanishing gradients.
- Normalize inputs: Batch normalization can stabilize and speed up training by normalizing layer inputs.
14. Explain the learning rate in a neural network.
The learning rate in a neural network is a critical hyperparameter that determines how much the model's weights are adjusted during each update in response to the gradient. It essentially controls the step size to minimize the loss function.
- If the learning rate is too low, the network will learn very slowly, taking a long time to converge to the minimum of the loss function. This can also cause the model to get stuck in local minima, as the steps taken are too small to overcome minor variations in the loss landscape. The slow learning process increases the computational cost of training.
- If the learning rate is too high, the model may overshoot the optimal point, missing the minimum of the loss function because the steps are too large. This can cause the network to diverge rather than converge or lead to oscillations where the loss function fluctuates without settling to a minimum.
15. What is the difference between model pre-training and fine-tuning?
- Pre-training: This is the initial phase where a model is trained on a large, generic dataset to acquire general knowledge. For example, training a language model on a vast text corpus from the internet to learn grammar, syntax, and common phrases.
- Fine-tuning: After pre-training, the model is further trained on a smaller, task-specific dataset. For instance, a model trained on general datasets can be fine-tuned on a medical dataset to specialize in medical-related tasks. Fine-tuning typically takes less time than pre-training due to the smaller size of the dataset.
Advanced Architectures
16. What are autoencoders?
Autoencoders are a neural network designed to learn efficient data representations, typically for dimensionality reduction.
An autoencoder takes an input, such as an image, and compresses it into a low-dimensional representation, known as a latent vector.
This latent vector is then used to reconstruct the original input. Regular autoencoders are trained to output the same image they receive as input.
17. What are the different layers in a CNN?
The convolution layer is key to reducing the image size, making processing more efficient and less computationally intensive.
It applies a feature detector (also known as a kernel or filter) over the input image. Typically, the kernel is a 3x3 matrix, though other sizes can be used. The convolution operation involves element-wise multiplication of the kernel with the input image and summing the results to produce a feature map.
This layer is fundamental to extracting features such as edges, textures, and patterns from the input image.
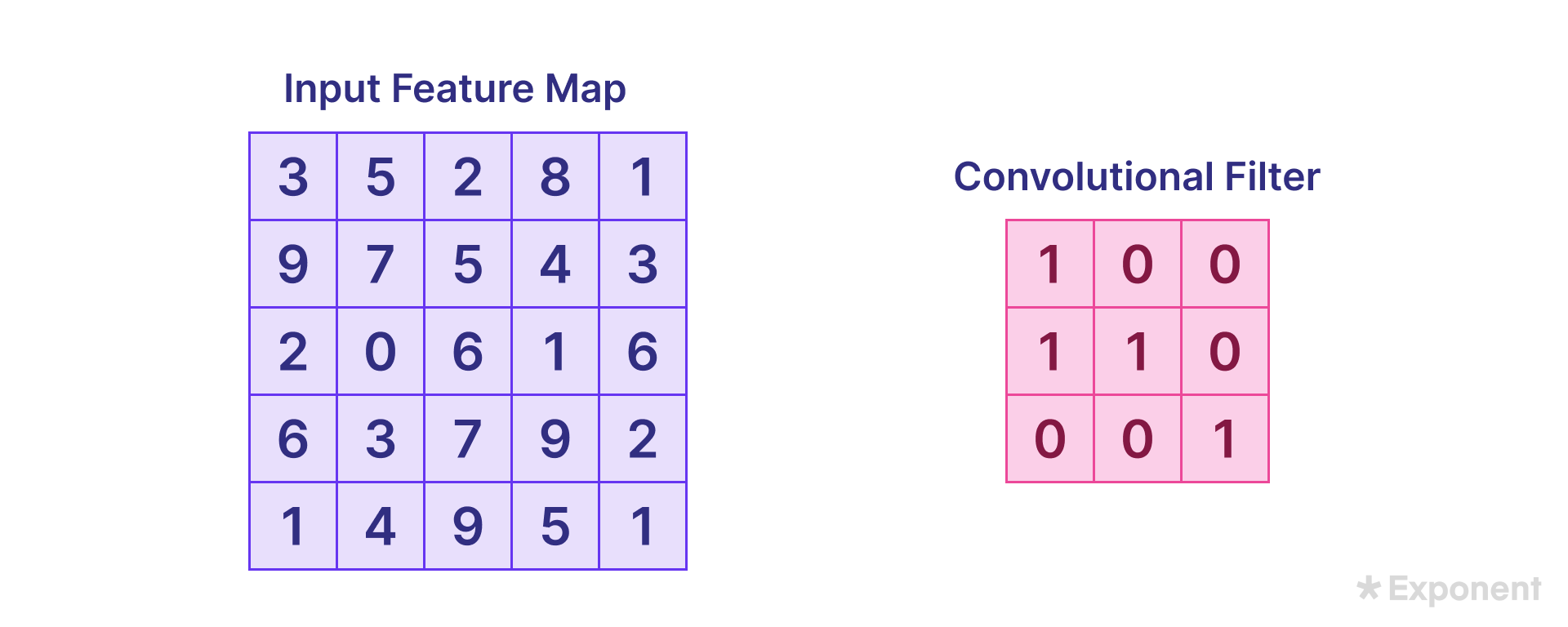
Given the input image and filter, the convolution operation is calculated as follows:
3 × 1 + 5 × 0 + 2 × 0 + 9 × 1 + 7 × 1 + 5 × 0 + 2 × 0 + 0 × 0 + 6 × 1 = 3 + 0 + 0 + 9 + 7 + 0 + 0 + 6 = 25
The kernel is then slid across the entire input image to compute all the values as shown above.
The kernel moves over the input image in steps known as strides. The stride length is defined when designing the network. The size of the resulting feature map depends on the stride and kernel size.
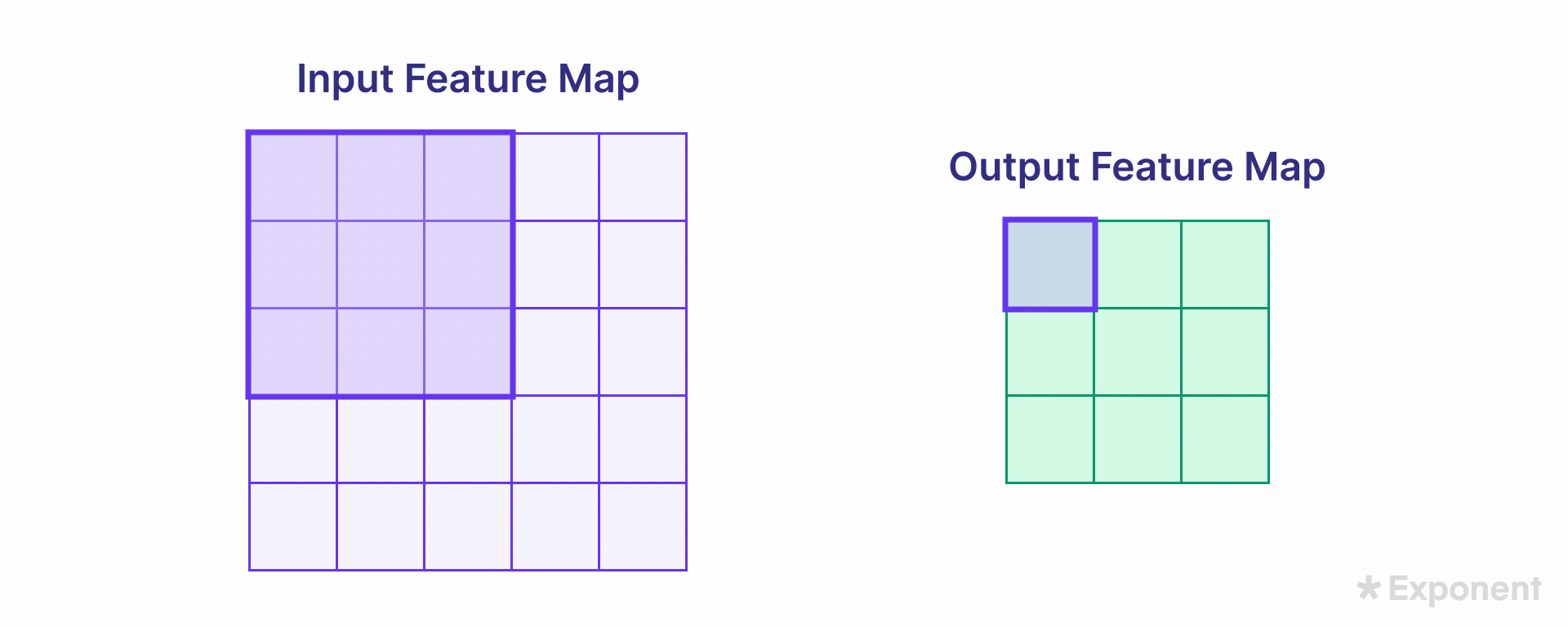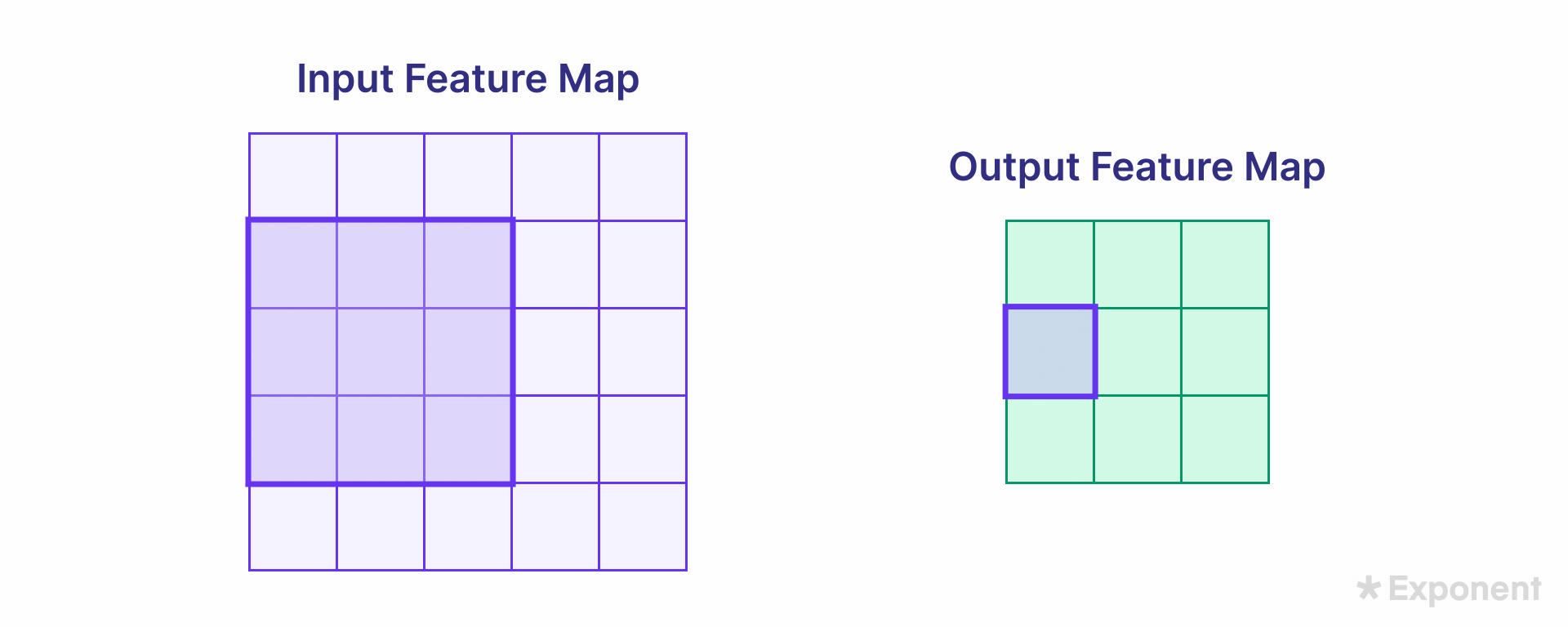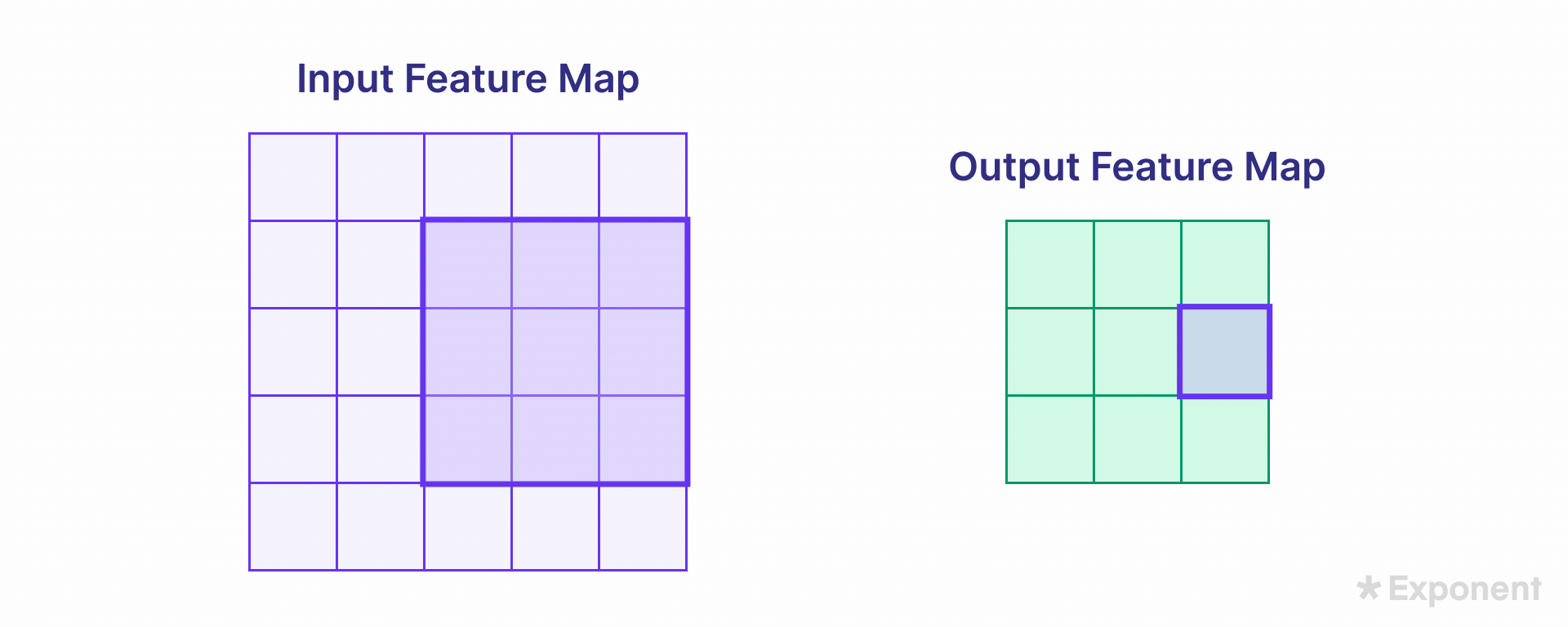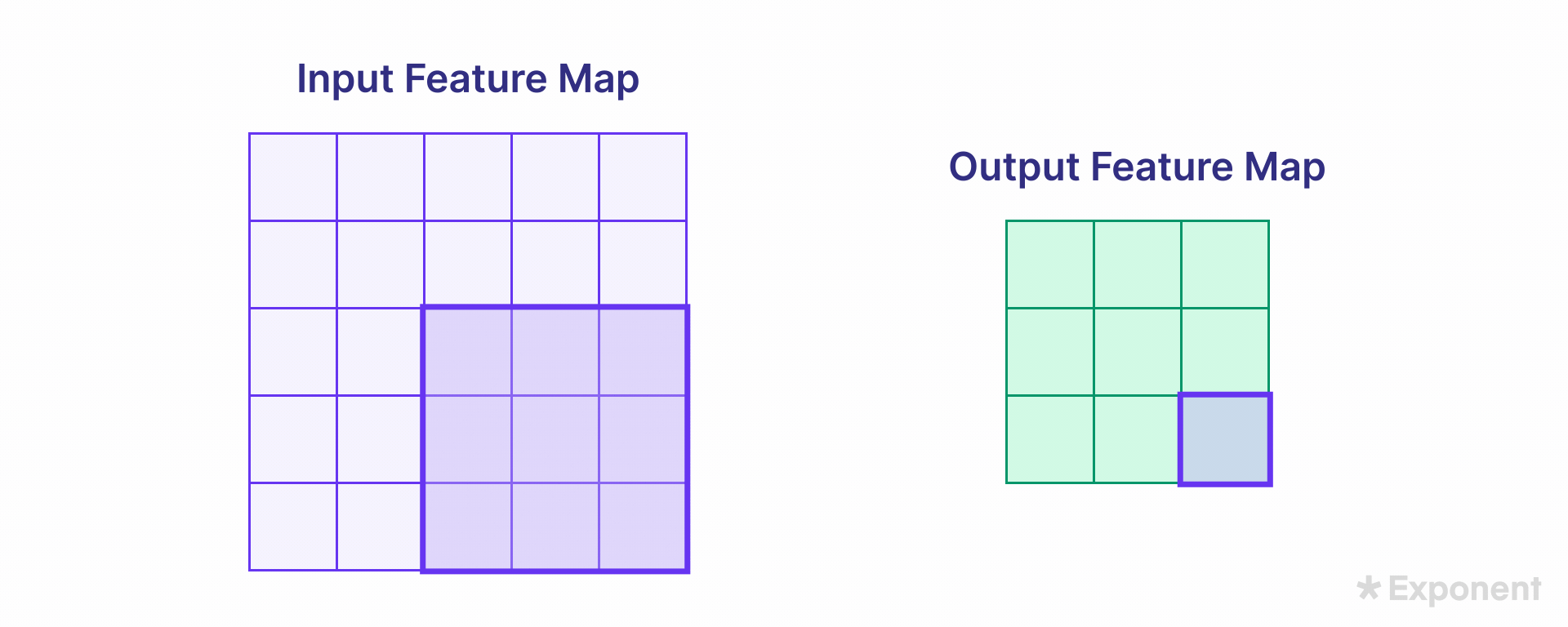
Padding ensures that the feature map size remains the same as the input image size. Padding involves adding zeros around the border of the input image so that, after the kernel is applied, the output retains the exact dimensions as the input. The padding type is specified during network creation.
The two common options are:
- Same: Pads the input so that the output feature map has the same size as the input.
- Valid: Applies no padding, resulting in a smaller feature map.
The uncolored area in a padded image represents the padded (zero-filled) region.
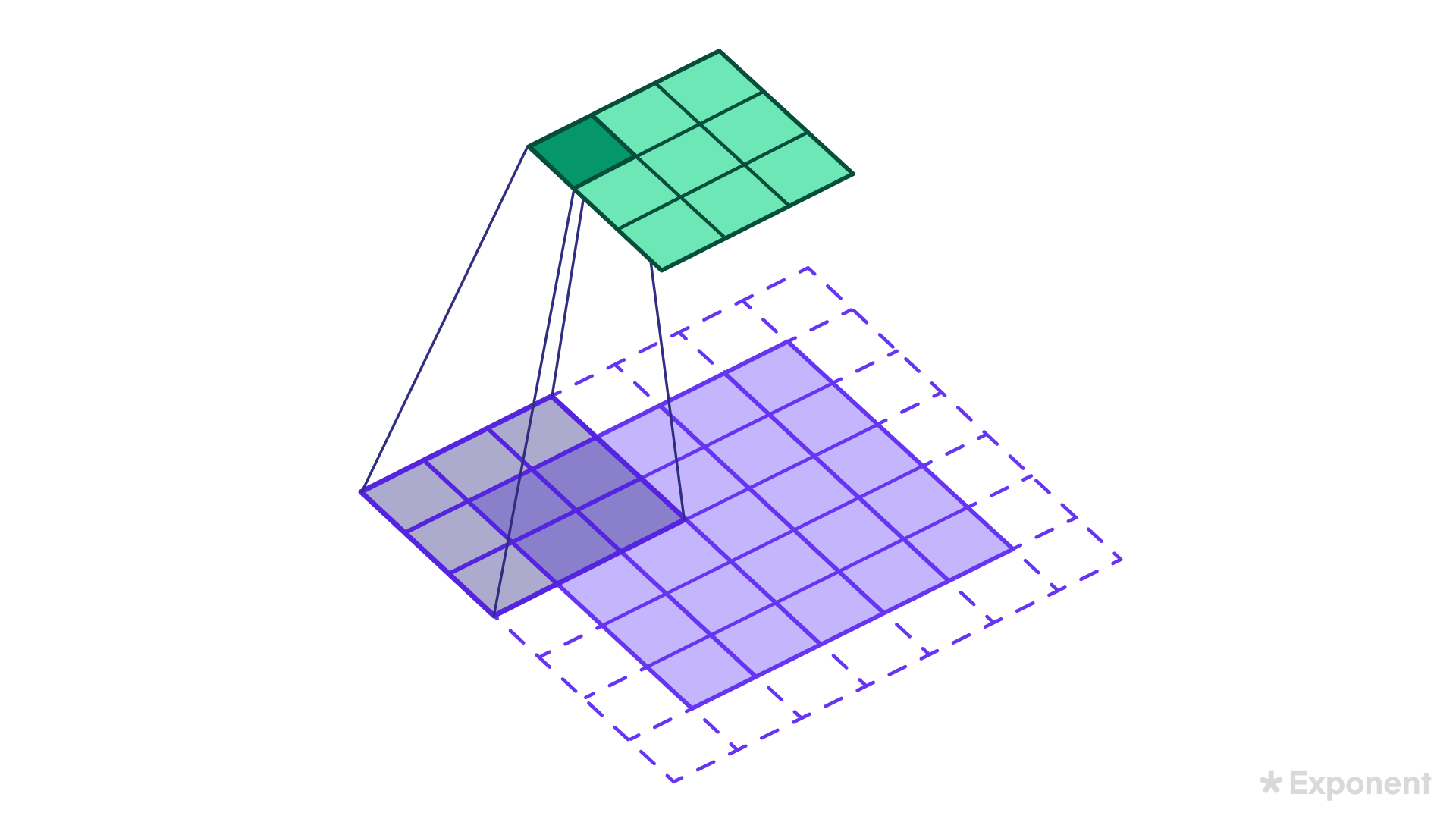
The Rectified Linear Unit (ReLU) layer is applied during the convolution operation to introduce non-linearity. ReLU forces all negative values to zero, while positive values are retained as they are.
The Pooling Layer further reduces the size of the feature map. This is done by applying a pooling filter, such as max pooling, which slides over the feature map and selects the maximum value in each region. For example, a 2x2 pooling filter applied to a 4x4 feature map reduces it to a 2x2 pooled feature map.
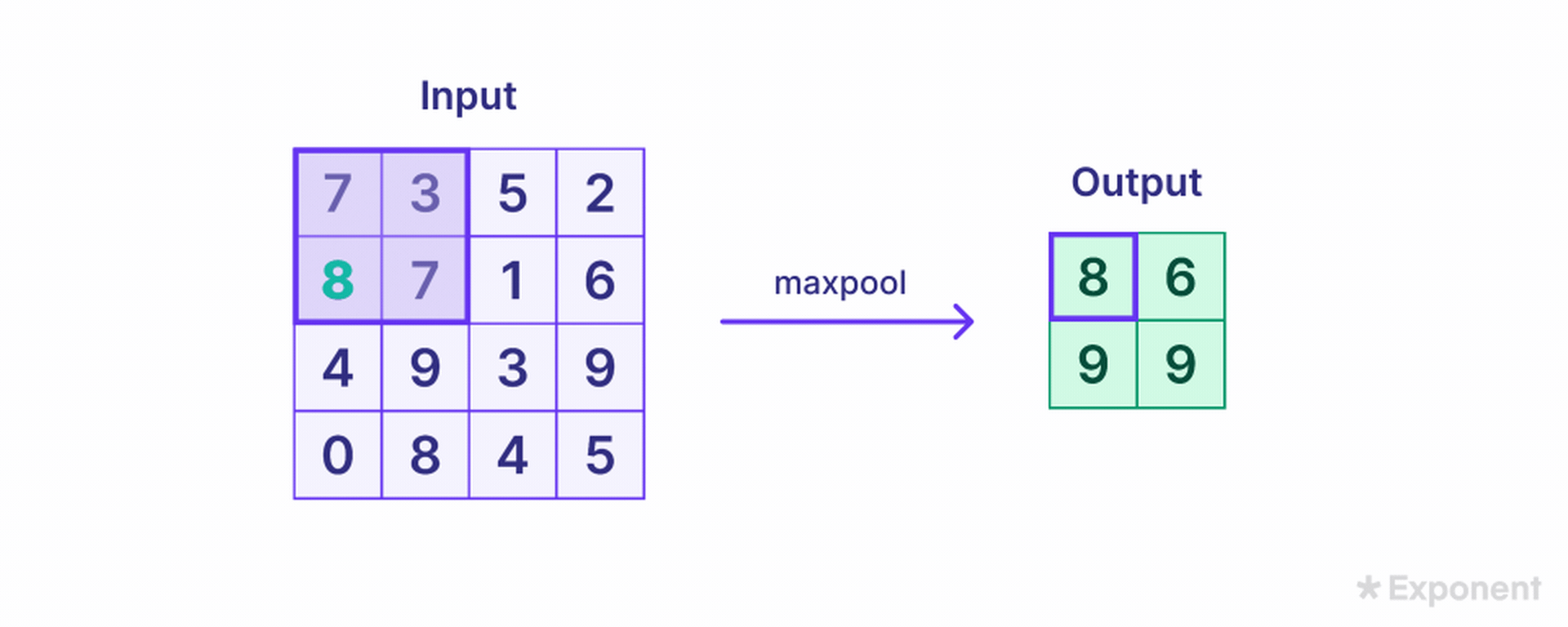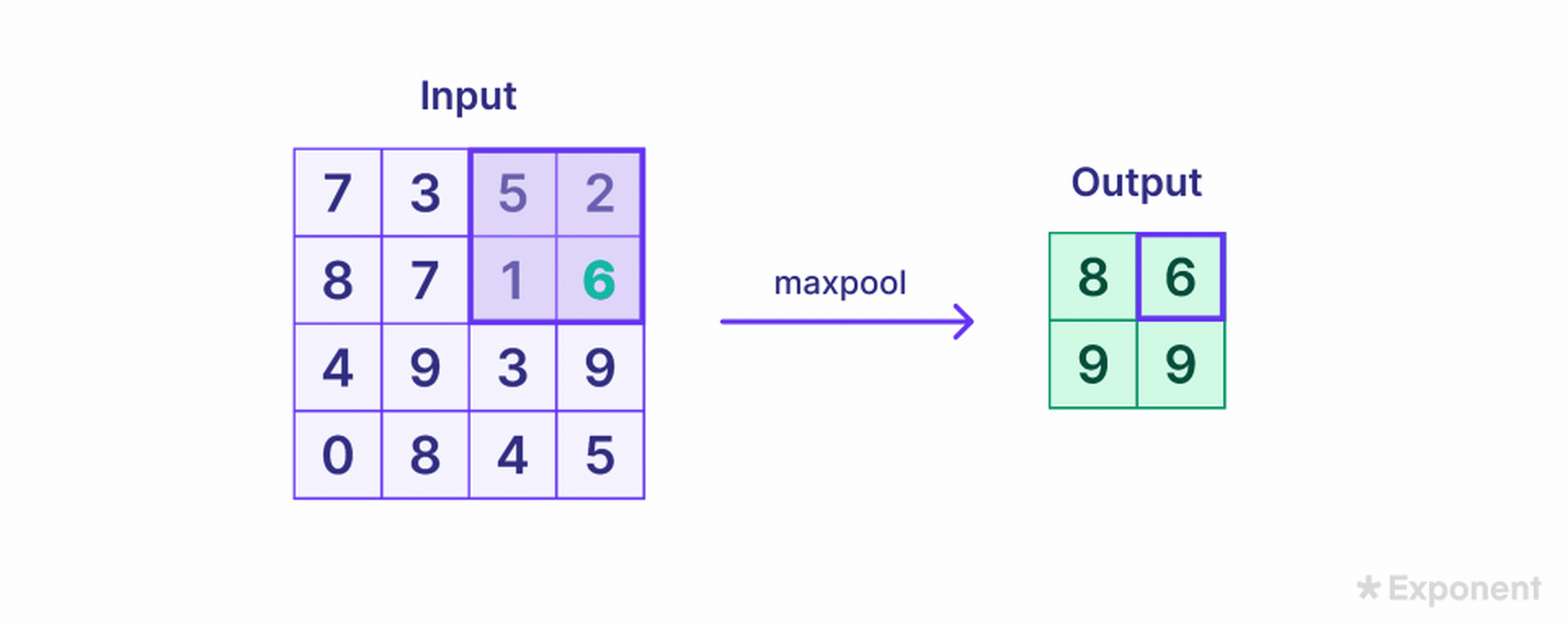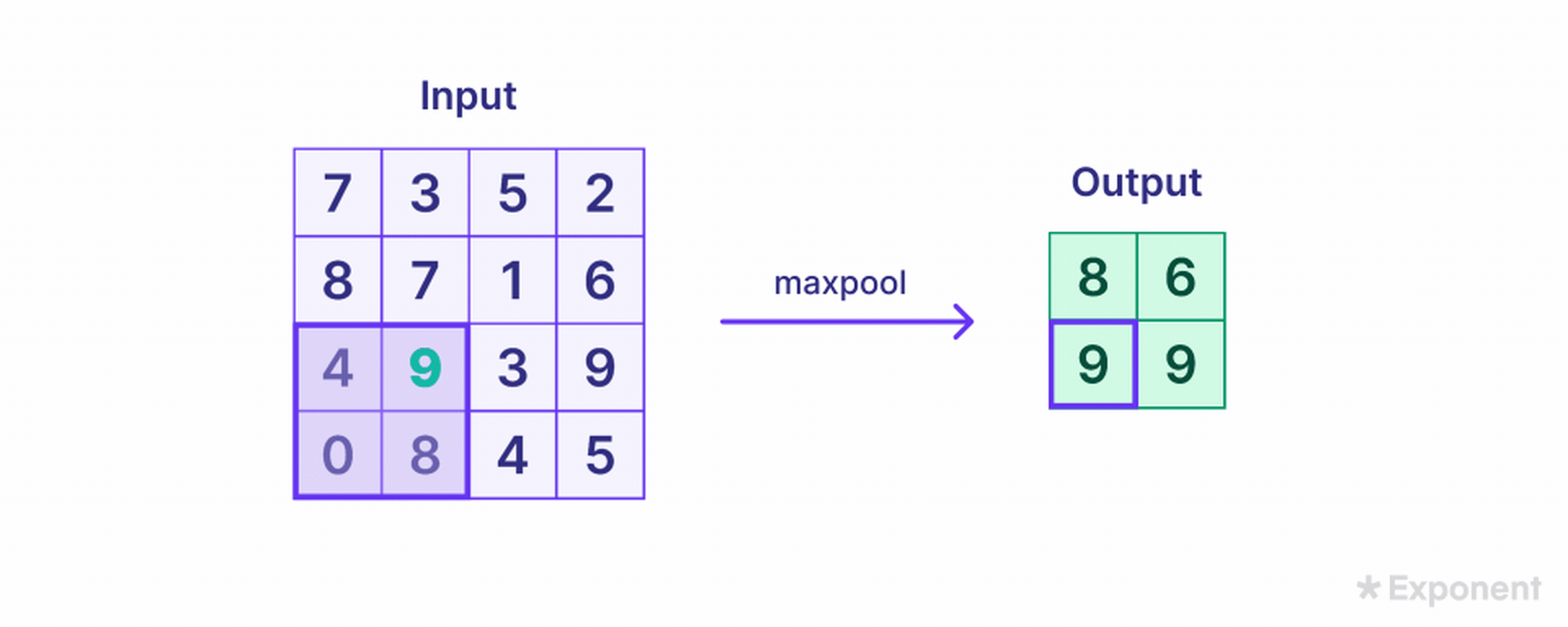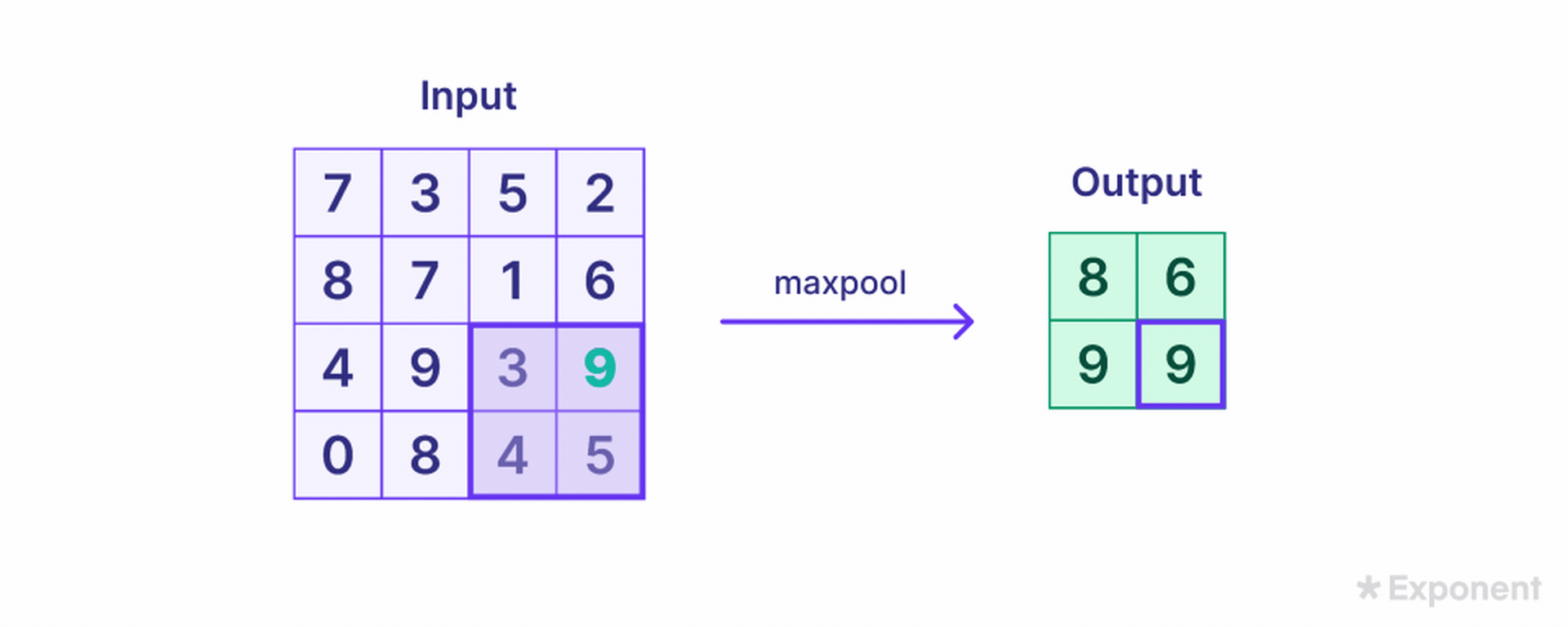
Dropout is often added to the network as a regularization technique to prevent overfitting. It randomly sets a fraction of the input units to zero during training.
The Flattening Layer converts the pooled feature map into a single column (a one-dimensional array), which is then passed to the fully connected (Dense) layer. This Dense layer is responsible for generating the final output. Depending on the problem type, an activation function is applied:
- Sigmoid is used for binary classification tasks.
- Softmax is used for multiclass classification tasks.
18. Why are transformers widely used in natural language processing tasks?
The Transformer architecture was introduced in the influential paper Attention Is All You Need.
Unlike traditional models, the Transformer doesn’t rely on recurrence or convolutions. Instead, it uses an attention mechanism, allowing faster training through parallelization.
The architecture consists of stacked self-attention and fully connected layers in the encoder and decoder, eliminating the need for recurrent networks.
The Transformer is widely used in natural language processing (NLP) tasks because:
- It supports parallel processing, making it more computationally efficient, especially for GPUs and other accelerators.
- Excels at modeling long-range dependencies, enabling it to learn and retain longer sequences of information effectively.
- It is highly effective at handling sequence data, essential for many NLP tasks.
19. What is gradient clipping?
Gradient clipping is a technique for preventing exploding gradients by limiting them to a maximum value. When the gradient's norm exceeds a specified threshold, it is clipped, which helps maintain stable training.
Gradient clipping in Keras using clipvalue:
# Gradients less than -0.5 will be capped to -0.5, and gradients above 0.5 will be capped to 0.5
model.compile(
optimizer=tf.keras.optimizers.Adam(clipvalue=0.5),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)Gradient clipping in Keras using clipnorm:
# If the vector norm of a gradient exceeds 1, the vector's values will be rescaled so that the norm equals 1.
model.compile(
optimizer=tf.keras.optimizers.Adam(clipnorm=1.0),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)20. Write a function that computes 2D convolution using PyTorch.
Here’s how to implement a 2D convolutional filter in PyTorch:
import torch
import torch.nn as nn
def conv2d(input, weight, bias=None, stride=1, padding=0):
"""
Computes the 2D convolution of an input tensor with a weight tensor.
Args:
input: A 4D tensor of shape (batch_size, in_channels, in_height, in_width).
weight: A 4D tensor of shape (out_channels, in_channels, kernel_height, kernel_width).
bias: A 1D tensor of shape (out_channels,) for bias values (optional).
stride: The stride of the convolution (default=1).
padding: The padding for the convolution (default=0).
Returns:
A 4D tensor of shape (batch_size, out_channels, out_height, out_width).
"""
# Get input and weight dimensions
batch_size, in_channels, in_height, in_width = input.shape
out_channels, _, kernel_height, kernel_width = weight.shape
# Create and initialize the 2D convolution layer
conv_layer = nn.Conv2d(in_channels, out_channels, kernel_size=(kernel_height, kernel_width), bias=bias, stride=stride, padding=padding)
conv_layer.weight = nn.Parameter(weight)
# Perform the convolution
return conv_layer(input)21. What is the difference between model pre-training and fine-tuning?
- Pre-training: This is the initial phase where a model is trained on a large, generic dataset to acquire general knowledge. For example, training a language model on a vast text corpus from the internet to learn grammar, syntax, and common phrases.
- Fine-tuning: After pre-training, the model is further trained on a smaller, task-specific dataset. For instance, a model trained on general datasets can be fine-tuned on a medical dataset to specialize in medical-related tasks. Fine-tuning typically takes less time than pre-training due to the smaller size of the dataset.
22. Describe the process of generating text using a transformer-based language model.
A transformer-based language model predicts the next word based on the context of previous words. The process starts with a prompt, which is converted into numerical tokens representing words or subwords.
These tokens are passed through an embedding layer that captures their semantic meaning, and position encoding is added to retain word order since transformers don't inherently understand sequence.
The tokens then go through self-attention layers, allowing the model to weigh each token's importance relative to others. This captures long-range dependencies in the text. The model outputs the probability of each word being the next word, and the next word is selected using strategies like greedy decoding, beam search, or top-k sampling.
The generated token is added to the sequence and fed back to the model to generate the next one. This process continues until the desired length is reached or an end-of-sequence token is generated. The final step is detokenization, where the tokens are converted back into text.
23. What is the purpose of zero_grad() in PyTorch, and when is it used?
The zero_grad() function in PyTorch resets all the gradients to zero.
Before starting a new backward pass, ensure that previous gradients do not interfere with the current training iteration.
Example of zero_grad() in PyTorch:
import torch
import torch.optim as optim
# Define a simple model and optimizer
model = torch.nn.Linear(1, 1)
optimizer = optim.SGD(model.parameters(), lr=0.01)
# Initialize input data and target
inputs = torch.randn(1, 1, requires_grad=True)
target = torch.randn(1, 1)
# Starting training loop
for _ in range(5): # run for 5 iterations
# Perform forward pass
output = model(inputs)
loss = torch.nn.functional.mse_loss(output, target)
# Perform backward pass and update model parameters
optimizer.zero_grad() # Zero the gradients
loss.backward() # Compute gradients
optimizer.step() # Update weights24. What is the difference between masked language modeling and causal language modeling?
- Causal Language Modeling predicts the next token in a sequence, only considering tokens to the left. It is unidirectional.
- Masked Language Modeling masks specific tokens in the input and trains the model to predict them. It considers tokens on both the left and right, making it bidirectional.
Practical Applications
25. How do you handle imbalanced datasets in deep learning?
Class weights can be introduced and passed to the model during training to handle imbalanced datasets.
weights = [1.013, 0.889, 1.007, 0.978, 1.027, 1.106, 1.013, 0.957, 1.025, 1.008]
model.compile(optimizer=tf.keras.optimizers.SGD(),
loss=tf.keras.losses.SparseCategoricalCrossentropy(),
loss_weights=weights,
metrics=['accuracy'])In addition to class weights, we can also undersample the majority class.
26. How do you implement a custom loss function in TensorFlow?
A custom loss function is defined by creating a function that accepts true and predicted values, returning the computed loss.
import tensorflow as tf
def custom_loss_function(y_true, y_pred):
squared_difference = tf.square(y_true - y_pred)
return tf.reduce_mean(squared_difference, axis=-1)
model.compile(optimizer='adam', loss=custom_loss_function)27. How do you implement a custom training loop in TensorFlow?
from tqdm.notebook import trange
import tensorflow as tf
# Track results for plotting
train_loss_results = []
train_accuracy_results = []
num_epochs = 10
for epoch in trange(num_epochs):
epoch_loss_avg = tf.keras.metrics.Mean()
epoch_accuracy = tf.keras.metrics.SparseCategoricalAccuracy()
# Training loop - using batches of 32
for x, y in training_data:
loss_value, grads = grad(model, x, y)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
# Track progress
epoch_loss_avg.update_state(loss_value) # Update current batch loss
epoch_accuracy.update_state(y, model(x, training=True)) # Update accuracy
# End of epoch
train_loss_results.append(epoch_loss_avg.result())
train_accuracy_results.append(epoch_accuracy.result())
print(f"Epoch {epoch + 1}: Loss: {epoch_loss_avg.result():.3f}, Accuracy: {epoch_accuracy.result():.3%}")28. What is the difference between Instance Segmentation and Semantic Segmentation?
- Semantic Segmentation assigns a label to each pixel in an image, categorizing regions based on object classes. For example, in an image with several people, every person is assigned the same label.
- Instance Segmentation, conversely, differentiates between instances of the same object. In the same example, each person would be assigned a separate mask, distinguishing one person from another.
29. Explain transfer learning.
Transfer learning is a technique where a model developed for one task is repurposed for a different but related task.
This approach is prevalent in computer vision and natural language processing, where pre-trained models serve as a foundation for new tasks, significantly reducing training time.
Pre-trained models are usually trained on large benchmark datasets, and their learned weights are applied to a new task with a smaller dataset. This method not only speeds up training but also helps to reduce the generalization error.
Steps to implement transfer learning:
- Obtain a pre-trained model.
- Create a base model using the pre-trained model.
- Freeze the layers of the base model to prevent them from being updated during training.
- Add new trainable layers to adapt the model to the new task.
- Train the new layers on your dataset.
- Fine-tune the model for improved performance.
Example implementation in TensorFlow:
import tensorflow as tf
# Define image size
IMAGE_SIZE = 224
# Load a pre-trained model
base_model = tf.keras.applications.MobileNetV3Small(
input_shape=(IMAGE_SIZE, IMAGE_SIZE, 3),
alpha=1.0,
include_top=True,
weights="imagenet",
input_tensor=None,
pooling=None,
classes=1000,
classifier_activation="softmax"
)
# Freeze the base model's layers
base_model.trainable = False
# Standardize the input
inputs = keras.Input(shape=(IMAGE_SIZE, IMAGE_SIZE, 3))
x = data_augmentation(inputs) # Apply random data augmentation
x = base_model(x, training=False)
x = keras.layers.GlobalAveragePooling2D()(x)
x = keras.layers.Dropout(0.2)(x) # Regularize with dropout
outputs = keras.layers.Dense(1)(x)
model = keras.Model(inputs, outputs)
# Fine-tune the model
base_model.trainable = False
# Unfreeze the last 5 layers for training
for layer in model.layers[:-5]:
layer.trainable = True30. What is Reinforcement Learning from Human Feedback (RLHF)?
RLHF is a method for aligning a large language model (LLM) with human preferences to make it safer and more valuable.
The steps include:
- Supervised fine-tuning of the pre-trained model with a high-quality prompt dataset.
- Reward model creation from the fine-tuned model. Human raters rank responses generated by the model, and the rankings are used to train a reward model.
- Fine-tuning with proximal policy optimization (PPO), using the reward model to adjust the model based on human feedback.
The reward model is created by:
- Generating 4-9 responses from the fine-tuned LLM.
- An individual ranks these responses based on their preference.
- The rankings dataset creates a reward model that outputs a reward score.
- To turn the model into a reward model, its classification layer is turned into a regression layer.
32. What are some challenges or ethical considerations associated with large language models?
Challenges include:
- Bias and fairness: Since models are trained on large datasets from the internet, they may inherit biases that could lead to discriminatory outcomes.
- Misinformation: As probabilistic models, LLMs may generate incorrect information, which is problematic in fact-based contexts.
- Privacy concerns: LLMs may inadvertently reveal private information learned during training, such as personal details.
- Environmental impact: Training large models requires significant computational resources, contributing to carbon emissions and raising sustainability concerns.
33. What problems are solved by retrieval-augmented generation?
Retrieval-augmented generation (RAG) enhances large language models by incorporating external data sources to reduce hallucinations and improve factual accuracy.
RAG retrieves relevant documents to inform the model’s output, ensuring it remains grounded in real data.
The RAG process involves:
- Loading relevant documents that may be useful for answering a query.
- Creating embeddings for the documents using an embedding model.
- Storing the documents and embeddings in a vector database.
- Querying the vector database with a retriever to find relevant documents based on similarity measures like cosine similarity.
- Passing the retrieved documents to the language model, which uses them to generate more accurate and context-aware answers.
Problems solved by RAG:
- Context Window Limitations: LLMs have a fixed input size, limiting the amount of data they can process simultaneously. RAG overcomes this by retrieving only the most relevant documents.
- Hallucinations: LLMs can generate plausible but incorrect information. By grounding the output in real documents, RAG minimizes hallucinations.
- Staleness of Information: LLMs are trained on static datasets and may not have access to recent information. RAG solves this by retrieving up-to-date documents.
- Source Trustworthiness: By retrieving real documents, RAG can provide sources for the answers it generates, increasing trust and verifiability.
- Private Information Leakage: RAG reduces the risk of private information leakage, as it retrieves and uses external data rather than relying on internal knowledge from training.
34. Why would you prefer CNNs over ANNs for image classification tasks, even though image classification is possible with ANNs?
CNNs are generally preferred over ANNs for image classification because:
- CNNs have fewer parameters due to the convolution and pooling operations, making them easier to train.
- CNNs are better at extracting important features from images, such as edges and textures, which are crucial for accurate image classification.
35. Discuss data augmentation techniques for computer vision.
Data augmentation is a method used to increase the diversity of images without collecting new data, making models more robust and capable of generalizing to unseen datasets. Common techniques include:
- Geometric transformations like rotation, scaling, shearing, and flipping.
- Color adjustments to brightness, hue, and contrast.
- Noise addition, such as Gaussian noise, to help the model handle noisy data.
- Mixup (combining two images) and CutMix (pasting a patch from one image onto another) to create novel examples.
36. Implement learning rate scheduling in PyTorch.
You can implement learning rate scheduling with torch.optim.lr_scheduler.
Common schedulers include:
StepLR,MultiStepLR,ExponentialLR,- and
ReduceLROnPlateau.
Example:
import torch
import torch.optim as optim
import torch.optim.lr_scheduler as lr_scheduler
import torch.nn as nn
# Model and optimizer
model = nn.Linear(10, 2)
optimizer = optim.SGD(model.parameters(), lr=0.1)
# Define LR scheduler
scheduler = lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.5)
# Training loop
for epoch in range(20):
optimizer.step()
scheduler.step()37. Implement a Variational Autoencoder (VAE) in TensorFlow/Keras
from tensorflow.keras.layers import Input, Conv2D, Flatten, Dense, Lambda, Reshape, Conv2DTranspose
from tensorflow.keras.models import Model
import tensorflow.keras.backend as K
import numpy as np
# Define input shape and latent dimension
latent_dim = 2
input_shape = (img_size, img_size, 3)
# Encoder network
inputs = Input(shape=input_shape)
x = Conv2D(16, (3, 3), activation='relu', padding='same')(inputs)
x = Conv2D(32, (3, 3), activation='relu', strides=(2, 2), padding='same')(x)
x = Conv2D(128, (3, 3), activation='relu', padding='same')(x)
x = Conv2D(256, (3, 3), activation='relu', padding='same')(x)
shape_before_flattening = K.int_shape(x)
x = Flatten()(x)
z_mean = Dense(latent_dim)(x)
z_log_var = Dense(latent_dim)(x)
# Sampling function
def sampling(args):
z_mean, z_log_var = args
epsilon = K.random_normal(shape=(K.shape(z_mean)[0], latent_dim))
return z_mean + K.exp(z_log_var / 2) * epsilon
# Reparameterization trick
z = Lambda(sampling)([z_mean, z_log_var])
# Decoder network
decoder_input = Input(K.int_shape(z)[1:])
x = Dense(np.prod(shape_before_flattening[1:]), activation='relu')(decoder_input)
x = Reshape(shape_before_flattening[1:])(x)
x = Conv2DTranspose(128, (2, 2), activation='relu', padding='same')(x)
x = Conv2DTranspose(64, (2, 2), activation='relu', padding='same', strides=(2, 2))(x)
x = Conv2DTranspose(32, (2, 2), activation='relu', padding='same')(x)
x = Conv2DTranspose(16, (2, 2), activation='relu', padding='same')(x)
x = Conv2D(3, (3, 3), activation='sigmoid', padding='same')(x)
# Define the VAE model
encoder = Model(inputs, [z_mean, z_log_var, z], name='encoder')
decoder = Model(decoder_input, x, name='decoder')
outputs = decoder(encoder(inputs)[2])
vae = Model(inputs, outputs, name='vae')38. What is Federated Learning?
Federated Learning allows devices to collaboratively improve a shared model without exchanging raw data.
Initially, the model is trained on proxy data, downloaded to individual devices, and refined using local data.
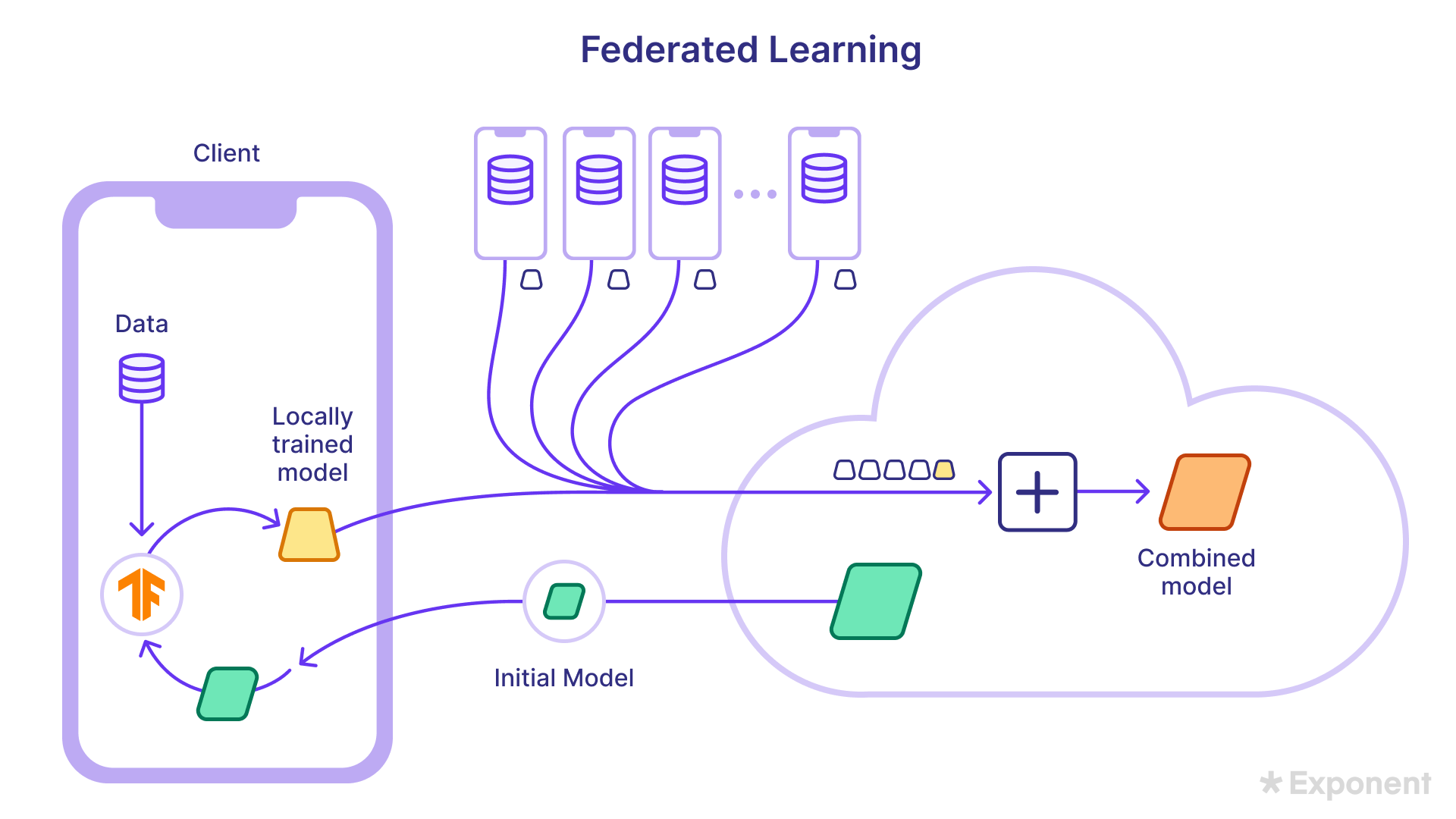
Key benefits include:
- Privacy: Sensitive data is not transmitted to the cloud.
- Lower latency and power consumption: Models are trained locally, reducing the need for server-side processing.
- Smarter models: Collaborative learning from decentralized data leads to better generalization.
39. Discuss model quantization for large language models.
Model quantization is a technique used to reduce large models' memory and computational requirements by lowering their weights' precision, such as converting from float32 to float16.
This enables the deployment of large models on resource-constrained environments like edge devices and mobile platforms.
Quantized models offer several benefits:
- Reduced memory footprint
- Faster inference times
- Lower power consumption
- Cost savings
There are two main types of quantization:
- Post-Training Quantization (PTQ): Quantization is applied after the model is trained without requiring access to training data. This method is more straightforward but may result in a slight loss of accuracy.
- Quantization-Aware Training (QAT): Quantization is integrated during training, allowing the model to adjust to lower precision, leading to better accuracy than PTQ.
Fundamental quantization techniques include:
- Weight Quantization: Reduces the precision of model weights.
- Activation Quantization: Lowers the precision of activations during model execution.
- Hybrid Quantization: Combines both weight and activation quantization to maximize efficiency.
Challenges of quantization include potential accuracy degradation and limited support for certain quantization methods on specific hardware.
Interview Tips
It is impossible to cover all the possible questions since deep learning is a broad and varied topic!
Hopefully, these questions have given you a glimpse into what to expect in deep-learning interviews.
- Explore our data science interview course's dozens of mock interviews and practice lessons.
- Schedule a free mock interview session to practice answering questions with peers.
- Get interviewing coaching from scientists at top companies.
Good luck with your upcoming machine learning interview!
Book time with a Machine Learning Engineer coach
- Mock interviews
- Career coaching
- Resume review
Learn everything you need to ace your machine learning interviews.
Exponent is the fastest-growing tech interview prep platform. Get free interview guides, insider tips, and courses.
Create your free accountRelated Courses

Machine Learning Engineer Interview Prep Course

Related Blog Posts

Top AI/ML Companies Hiring Now

