Machine learning interview questions span four rounds: ML concepts, coding, system design, and behavioral. This guide pulls 50+ real questions from our machine learning question bank and from recent candidate interviews, each with an answer and, where a candidate reported it, the company that asked the question.
Two shifts stand out for 2026: GenAI and LLM rounds now sit alongside classic ML theory, and safety-focused labs are folding ethics and alignment into technical rounds.
Top 10 machine learning interview questions
These ten questions come up most often across ML engineer loops, mixing classic theory with the GenAI and system design questions that appeared in 2025 and 2026 interviews:
- Explain gradient descent. (OpenAI)
- Explain linear vs. logistic regression. (Google)
- What is overfitting, and how do you avoid it? (Pinterest)
- Explain the bias-variance tradeoff.
- Design an evaluation framework for ads ranking. (Meta)
- Design a recommendation system for Spotify. (Spotify)
- Design an inference batching system for a single GPU. (Anthropic)
- How do you evaluate an LLM's performance? (Snap)
- Implement k-means clustering.
- Explain the architecture of a CNN. (Nvidia)
Most ML engineer loops still emphasize coding and ML fundamentals, so read that candidate's experience as a signal for labs like Anthropic rather than a universal pattern.
ML conceptual questions
Conceptual rounds test your grasp of fundamental machine learning and statistical concepts. Interviewers group them into four areas: data handling, model selection and optimization, evaluation methods and metrics, and ML in production.
1. What is overfitting? How can you avoid it?
Overfitting happens when a model learns specific details and noise in the training data, so it performs well on the training set but generalizes poorly to unseen data. Good training accuracy paired with poor test accuracy is the tell.
Common fixes: data splitting, regularization (L1 and L2), data augmentation, early stopping, and reducing model complexity.
2. Explain the bias-variance tradeoff.
The bias-variance tradeoff is the tension between a model that's too simple and one that's too complex. Bias is error from an overly simple model that misses real structure; variance is sensitivity to the training data that produces overfitting. Simpler models carry higher bias, complex models carry higher variance. Dataset splitting, appropriate model selection, and regularization keep the two in balance.
3. What is hyperparameter tuning?
Hyperparameter tuning is the search for the mix of hyperparameters that gives the best model performance. Hyperparameters control the learning process and are set before training, unlike parameters the model learns. Common examples include the train-test split ratio, activation function, and number of hidden layers. Best practice uses a validation set with cross-validation, grid or random search, and side-by-side performance comparison.
4. How do you handle missing or corrupted data? Name some imputation techniques.
Handling missing or corrupted data starts with identifying the missing values, then choosing between deletion and imputation. Common imputation techniques:
- Mean/median/mode imputation: Fill with the column's central value. Simple, but it can introduce bias.
- KNN imputation: Use the k nearest neighbors to estimate the missing value from similar samples.
- Iterative imputation: Predict missing values from the other features in repeated passes for a better estimate.
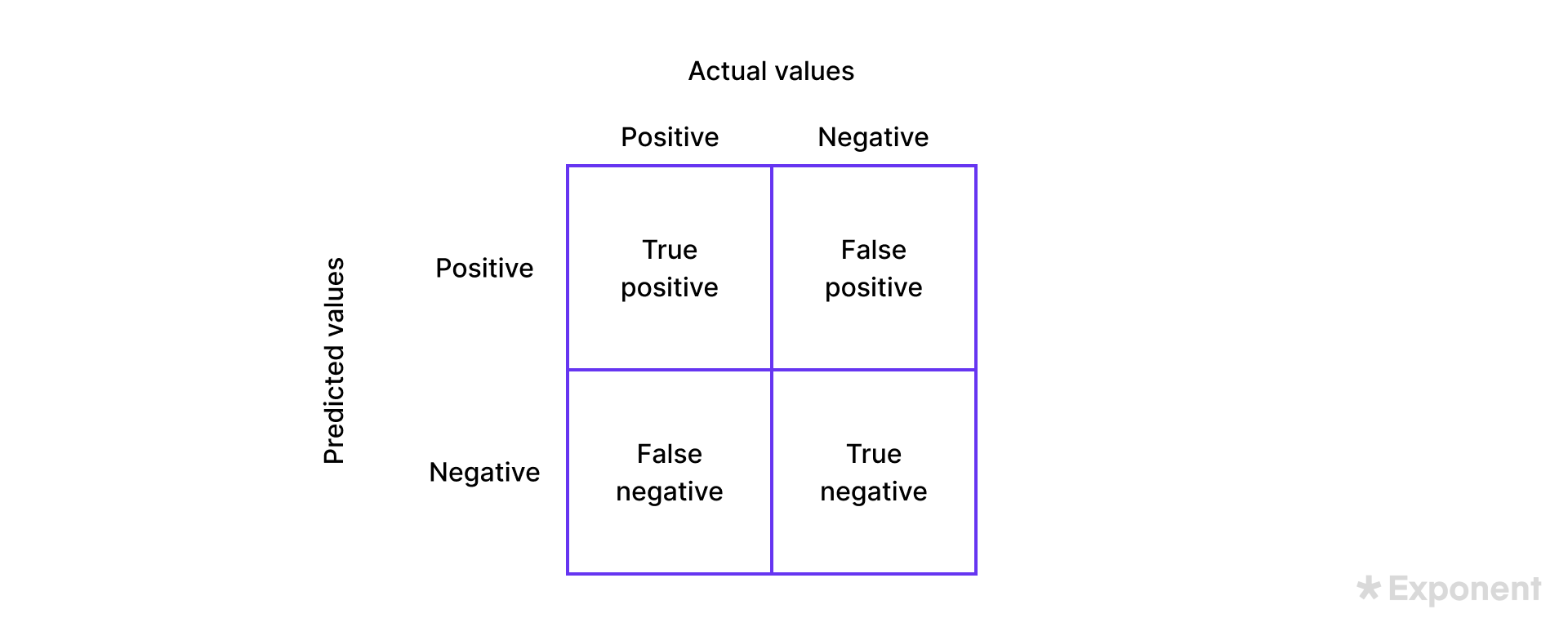
5. Explain a confusion matrix.
A confusion matrix evaluates a classifier by laying out actual vs. predicted classes in a grid.
Each cell is one of four outcomes: true positive (correct positive), true negative (correct negative), false positive (Type I error), and false negative (Type II error). From these you compute accuracy, precision, recall, and F1, which together show both how often the model is right and what kind of errors it makes.
6. What are false positives and false negatives?
A false positive is a negative case the model labels positive, like a legitimate email flagged as spam. A false negative is a positive case the model labels negative, like spam that reaches the inbox.
Which error matters more depends on the domain: false positives are costly in facial recognition and fraud flags, false negatives are costly in disease diagnosis.
7. How do you pick a suitable machine learning algorithm for a given task?
Choosing an algorithm starts with the task type and the data. Classify the task (classification, regression, or clustering), then account for dataset size, format, linearity, and quality. Set speed and accuracy thresholds, shortlist a few candidate algorithms, run cross-validation to guard against overfitting, and pick the best performer.
8. Explain principal component analysis (PCA) and its significance.
PCA is a dimensionality-reduction technique that generates new features, called principal components, from the existing ones. It standardizes the data, computes the covariance matrix, then derives eigenvectors and eigenvalues that capture the direction and magnitude of variance.
Sorting by the largest eigenvalues keeps the most informative components. PCA cuts computational cost, can reduce overfitting, and makes high-dimensional data easier to visualize.
9. Explain the architecture of a CNN.
A convolutional neural network (CNN) is a deep-learning architecture built for computer-vision tasks.
A typical CNN stacks: input layers (raw image vectors), convolutional layers (filters that extract edges, shapes, and colors into feature maps), pooling layers (dimensionality reduction via max or average pooling), activation layers (non-linearity for complex patterns), fully connected layers (classification), and an output layer.
10. Explain batch, mini-batch, and stochastic gradient descent.
Batch, mini-batch, and stochastic gradient descent differ in how much data each parameter update uses.
Gradient descent minimizes a loss function by stepping in the direction of steepest descent, using the derivative of loss with respect to the model's parameters. The three variants differ in how much data each step uses:
- Batch gradient descent: Computes the gradient over the entire training set, then takes one step.
- Mini-batch gradient descent: Splits the training set into small batches and steps once per batch.
- Stochastic gradient descent: Shuffles the data and updates on very small batches, trading smoothness for speed.
11. Describe precision, recall, and F1-score. When would you use each?
Precision measures how many predicted positives are correct, and matters when a false positive is expensive (spam filtering, healthcare). Recall measures how many actual positives you caught, and matters when a miss is expensive (disease detection). F1 is the harmonic mean of the two, useful on imbalanced datasets.
These three metrics evaluate a classifier's performance, and the right one depends on the cost of each error type.
12. What is the difference between one-hot encoding and label encoding?
One-hot encoding represents each category as a binary vector, treating categories as independent but increasing dimensionality. Label encoding assigns an integer per category, keeping dimensionality flat but risking a false ordinal relationship if the model reads the integers as ranks.
Both convert categorical features to numbers, but they trade off dimensionality against ordering assumptions.
13. How do you ensure data quality in ML tasks?
Data quality runs across the whole pipeline rather than a single step:
- Acquire data from reliable sources and confirm its origin and format.
- Handle missing values, inconsistencies, and outliers.
- Explore the distribution and check for patterns.
- Standardize or normalize features, and engineer the useful ones.
- Split into validation and test sets, and use cross-validation to check generalizability.
- Track model performance and errors to catch bias.
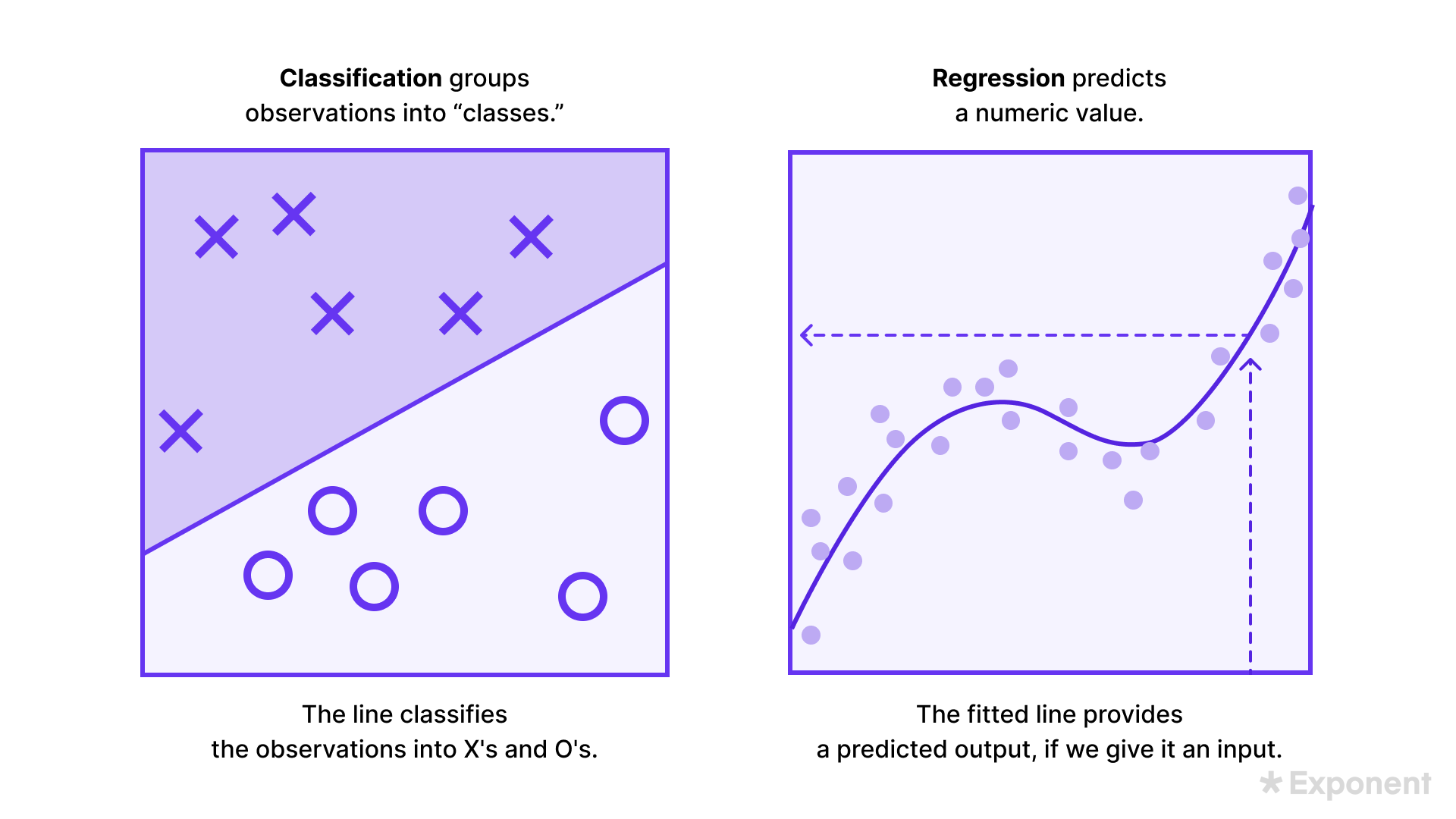
14. Explain classification vs. regression.
Classification and regression differ by what the supervised model predicts. Classification predicts categories (Yes/No, Hot/Cold); regression predicts continuous values (a person's height).
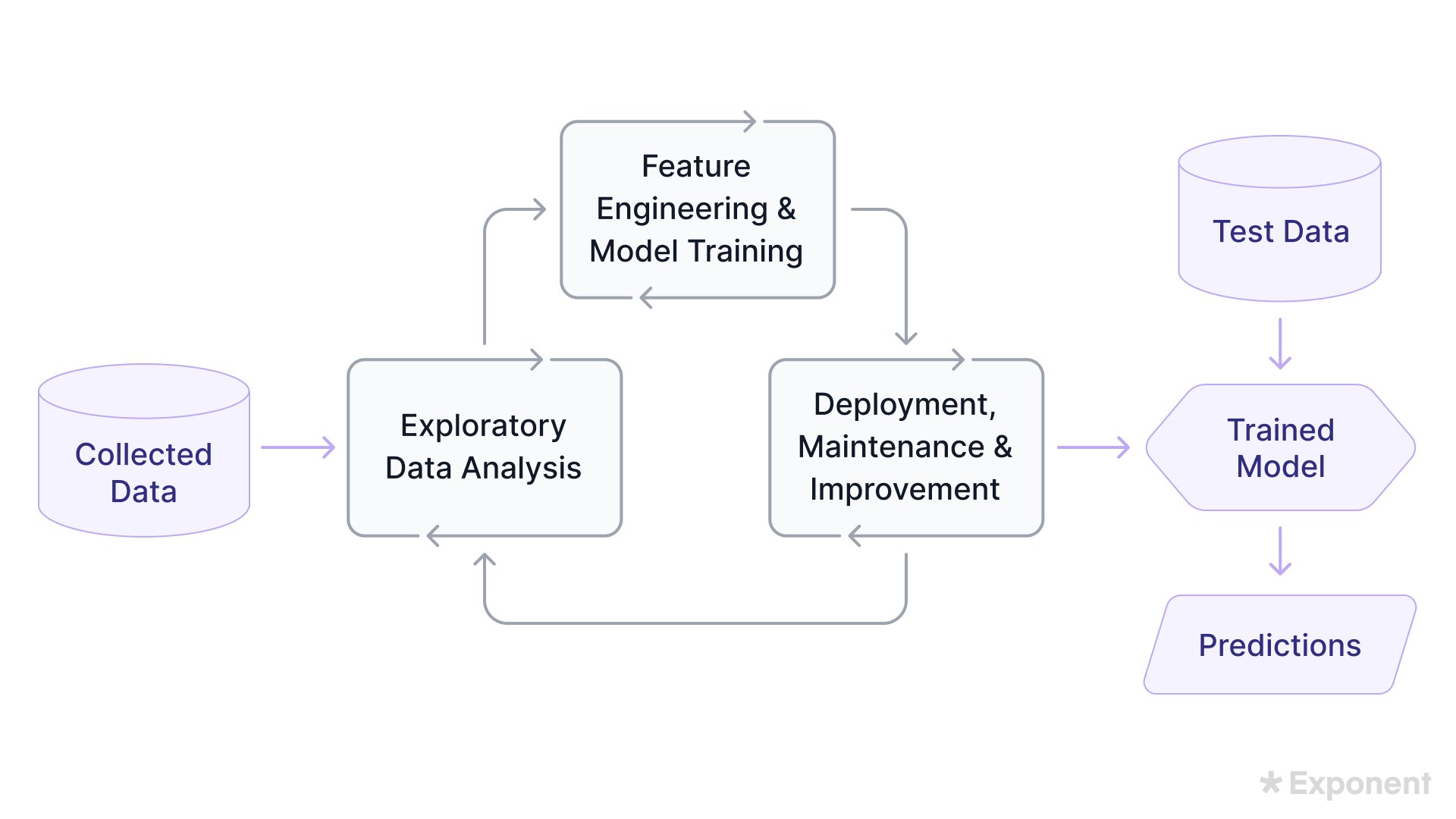
15. Explain the lifecycle of a machine learning application.
The machine learning lifecycle is the end-to-end process of building, deploying, and maintaining a model. Its stages:
- Problem definition and business understanding
- Data acquisition and exploration
- Data cleaning and preprocessing
- Model selection and training
- Evaluation on unseen data
- Deployment
- Monitoring in production
- Iterative refinement from feedback
16. Explain the concept of dropout in neural networks.
Dropout is a regularization technique that prevents overfitting by randomly dropping neurons during training. Forcing the network to learn without depending on any single neuron improves how well it generalizes to unseen data.
17. How does batch normalization work? What are its benefits?
Batch normalization addresses internal covariate shift, which can slow learning.
It computes the mean and standard deviation of each layer's activations per mini-batch, standardizes them, then applies learnable gamma (scale) and beta (shift) so the layer can recover useful representation. The payoff is faster convergence, reduced sensitivity to initialization, and support for higher learning rates.
18. How do you handle an imbalanced dataset?
Handling an imbalanced dataset starts with the right metric, since accuracy hides imbalance; F1 is usually a better fit. From there, rebalance the classes with oversampling (SMOTE) or undersampling, try a balanced bagging classifier, or apply threshold moving so the model separates the classes more effectively.
19. What are the different types of machine learning?
There are three core types of machine learning, plus two common hybrids:
- Supervised learning trains on labeled data (spam filtering).
- Unsupervised learning finds hidden structure in unlabeled data (clustering).
- Reinforcement learning learns by trial and error under a reward signal (self-driving cars).
Semi-supervised learning mixes labeled and unlabeled data, and deep learning uses neural networks to capture complex patterns.
20. Explain "training" and "testing" data.
Training data is the portion a model learns from; test data is the held-out portion used to measure how it performs on unseen examples.
21. What is a recommendation system, and how does it work?
A recommendation system filters items to match user preferences from interaction data (history, ratings, reviews). Collaborative filtering recommends items liked by similar users; content-based filtering recommends items similar to a user's past interactions. Most production systems blend both.
22. What is the curse of dimensionality?
The curse of dimensionality is the set of issues that appear as feature counts grow. High-dimensional space is mostly empty (data sparsity), distance-based methods like k-nearest neighbors degrade, models overfit more easily, and computation gets expensive.
23. Explain the support vector machine (SVM).
An SVM is a supervised classifier that separates classes with the maximum-margin hyperplane. The points closest to that boundary are the support vectors, and the algorithm maximizes the distance between classes.
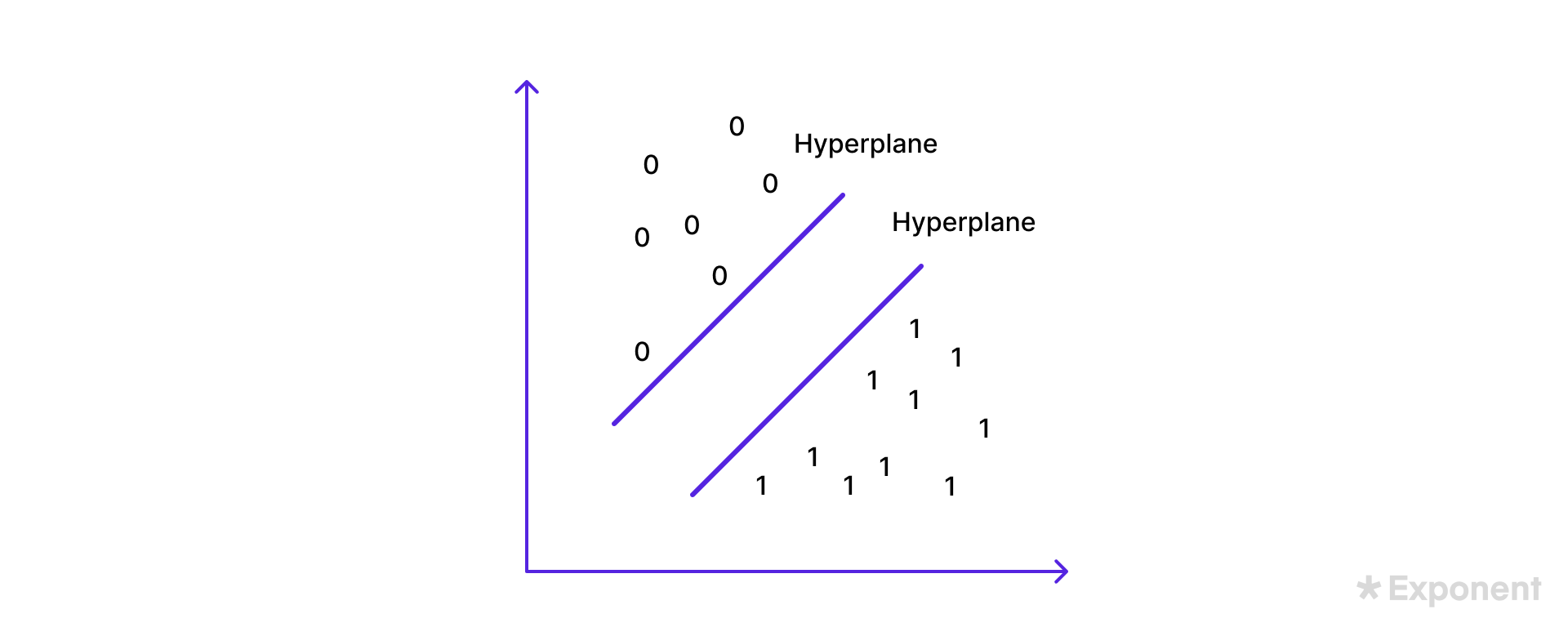
24. What is the difference between random forests and decision trees?
Both random forests and decision trees map feature rules to a target label through a tree structure, but they differ in variance. A decision tree builds one tree on all features and overfits easily. A random forest is an ensemble of trees trained on random subsets, which reduces overfitting and generalizes better.
25. Explain ETL.
ETL stands for Extract, Transform, Load:
- Extract pulls data from sources (databases, files, APIs).
- Transform cleans and standardizes it for consistency.
- Load writes the result into the target system for analysis.
ML coding questions
Machine learning coding questions test your fluency with ML frameworks (TensorFlow, PyTorch) and core ML concepts for the team's sub-field.
Here's a reliable structure for answering:
- Understand the prompt (5-7 min)
- Outline the approach in pseudocode and get buy-in (3-5 min)
- Implement in your chosen framework while thinking out loud (20-25 min)
- Test and discuss results (7-8 min)
1. Pre-process a dataset for a machine learning task.
Pre-processing a dataset tests whether you can build a clean pipeline and spot chances for feature manipulation. A pseudocode solution using scikit-learn:
import pandas as pd
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import LabelEncoder, StandardScaler
from sklearn.model_selection import train_test_split
data = pd.read_csv("data.csv")
print(data.isnull().sum())
imputer = SimpleImputer(strategy="mean")
data = pd.DataFrame(imputer.fit_transform(data))
categorical_cols = [c for c in data.columns if data[c].dtype == object]
le = LabelEncoder()
for c in categorical_cols:
data[c] = le.fit_transform(data[c])
scaler = StandardScaler()
numerical_cols = [c for c in data.columns if data[c].dtype != object]
data[numerical_cols] = scaler.fit_transform(data[numerical_cols])
X = data.drop("target_column", axis=1)
y = data["target_column"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)2. Evaluate a model on a held-out test set.
Evaluating a model on a held-out set checks whether you can measure performance and pick the right metrics. A pseudocode solution using scikit-learn:
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
from sklearn.linear_model import LogisticRegression
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
model = LogisticRegression()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
print("Accuracy:", accuracy_score(y_test, y_pred))
print("Precision:", precision_score(y_test, y_pred))
print("Recall:", recall_score(y_test, y_pred))
print("F1-score:", f1_score(y_test, y_pred))3. Fine-tune a pre-trained deep learning model.
Fine-tuning adapts a pre-trained model to a new dataset, which shows you understand transfer learning in practice. A pseudocode solution using TensorFlow:
from tensorflow.keras.applications import VGG16
from tensorflow.keras.layers import Flatten, Dense
from tensorflow.keras.models import Model
base_model = VGG16(weights="imagenet", include_top=False, input_shape=(img_height, img_width, 3))
for layer in base_model.layers:
layer.trainable = False
x = base_model.output
x = Flatten()(x)
x = Dense(1024, activation="relu")(x)
predictions = Dense(num_classes, activation="softmax")(x)
model = Model(inputs=base_model.input, outputs=predictions)
model.compile(optimizer="adam", loss="categorical_crossentropy", metrics=["accuracy"])4. Code a linear regression model.
A hands-on check of your coding, attention to detail, and how you explain a solution. A pseudocode solution using scikit-learn:
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import cross_val_score
lr = LinearRegression()
model = lr.fit(X_train, y_train)
y_pred = lr.predict(X_test)
scores = cross_val_score(lr, X_train, y_train, cv=5)
print("Accuracy score of each fold:", scores)
print("Mean accuracy score:", scores.mean())5. Implement k-means clustering.
K-means partitions a dataset into k non-overlapping clusters by similarity, using Euclidean distance to assign points to the nearest centroid.
import numpy as np
class Centroid:
def __init__(self, location, vectors):
self.location = location
self.vectors = vectors
class KMeans:
def __init__(self, n_features, k):
self.n_features = n_features
self.centroids = [
Centroid(np.random.randn(n_features), np.empty((0, n_features)))
for _ in range(k)
]
def distance(self, x, y):
return np.sqrt(np.dot(x - y, x - y))
def fit(self, X, n_iterations):
for _ in range(n_iterations):
for centroid in self.centroids:
centroid.vectors = np.empty((0, self.n_features))
for x_i in X:
distances = [self.distance(x_i, c.location) for c in self.centroids]
min_idx = distances.index(min(distances))
cur = self.centroids[min_idx].vectors
self.centroids[min_idx].vectors = np.vstack((cur, x_i))
for centroid in self.centroids:
if centroid.vectors.size > 0:
centroid.location = np.mean(centroid.vectors, axis=0)
def predict(self, x):
distances = [self.distance(x, c.location) for c in self.centroids]
return distances.index(min(distances))6. Split a dataset into training, evaluation, and testing sets.
Size each split to the dataset, holding out separate evaluation and test sets so you can tune without leaking into the final check.
from sklearn.model_selection import train_test_split
X_train, X_test_val, y_train, y_test_val = train_test_split(X, y, test_size=0.2, random_state=42)
X_test, X_val, y_test, y_val = train_test_split(X_test_val, y_test_val, test_size=0.5, random_state=42)ML system design questions
ML system design rounds test whether you can take a real product, define data and models, and reason about scale, monitoring, and tradeoffs out loud.
Recent interviews show the format widening from recommendation and detection systems to GenAI infrastructure. For full walkthroughs, worked examples, and a scoring rubric, read the machine learning system design interview guide.
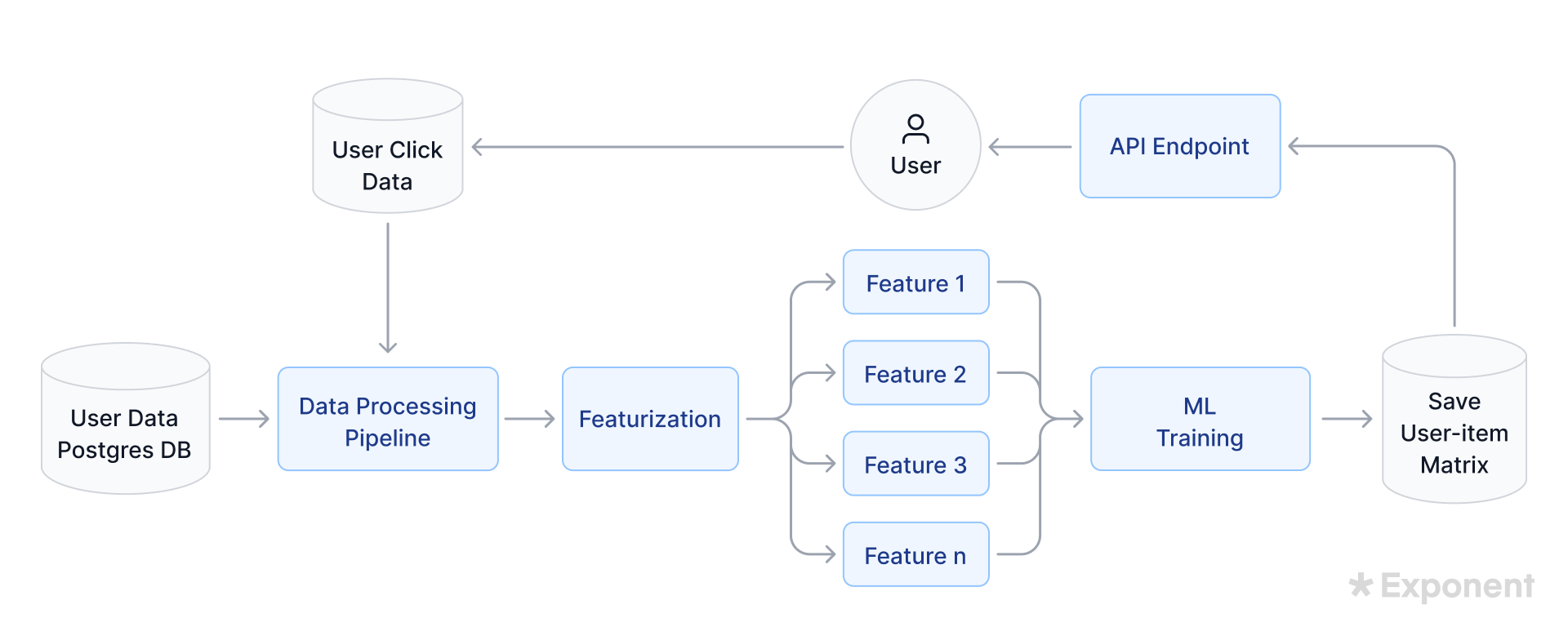
Here are some ML system design questions reported in recent ML engineer loops:
- Design an inference batching system for a single GPU that handles up to 100 inputs per batch while users wait synchronously. (Anthropic)
- Design an ML experiment tracking and analysis platform. (Google)
- Design a next-word prediction system.
- Design an end-to-end ML solution to detect ads selling weapons. (Meta)
- Design an evaluation framework for ads ranking. (Meta)
• "Functional requirements: A user can send an input and wait for the result; group up to 100 individual requests into a single GPU; return each result to the requester when done.
• Non-functional: Minimize idle time between batches, error on batch failure, scale to multiple GPUs.
• Core entities: Request, Batch, Result."
This is the kind of requirements-first opening interviewers look for before any architecture.
ML behavioral interview questions
Machine learning behavioral rounds assess your values, work style, and how you communicate technical work. Prepare specific stories for successes, failures, conflicts, and challenges, and give enough context that the interviewer can follow the situation, your actions, and the result.
Here are some recently asked behavioral questions:
- Describe your machine learning experience.
- Tell me about a project you worked on with a tight deadline. (Amazon, Google, Meta)
- Tell me about a time you handled a difficult stakeholder. (Amazon, Apple)
- Tell me about trends and challenges in your machine learning specialty.
- Describe a time you overcame a difficult situation.
FAANG+ ML interview questions
These questions recur across ML interviews at Google, Netflix, Amazon, Apple, and Meta, with Anthropic, Nvidia, and OpenAI now common on the ML engineer track too.
1. What is the interpretation of the ROC area under the curve?
The ROC curve plots the tradeoff between sensitivity and specificity for a binary classifier, and the area under it summarizes performance. An AUC of 0.5 is random; closer to 1 is better.
2. What are the methods of reducing dimensionality?
There are two broad approaches to reducing dimensionality: feature selection and feature extraction. Feature selection keeps the most predictive existing features using filter, wrapper, or embedded methods. Feature extraction builds new features from the originals, with LDA and PCA the most common techniques.
3. Design a product recommendation system.
When an interviewer asks you to design a product recommendation system, they want to see structured, real-world ML thinking. Open with clarifying questions (What's the product? Who's the audience? What's the goal?), start with a rule-based model to gather data, then move to a learned model. Define the North Star metric (for example, watch time) and secondary metrics (clicks, retention, engagement), and validate with A/B testing.
4. What are the different types of activation functions?
Activation functions add the non-linearity that lets a network learn complex patterns; without one, the network collapses to linear regression. Common types:
- Sigmoid (0-1 output, prone to vanishing gradients)
- Softmax (multi-class output)
- ReLU (passes positives, zeros negatives, can cause dying neurons)
- Leaky ReLU (a small negative slope to fix dying ReLU)
5. Explain the vanishing gradient.
A vanishing gradient happens when gradients shrink toward zero during backpropagation, so weights barely update and learning stalls. It comes from multiplying many small gradients through deep layers, often via activation functions that squash large inputs into a narrow range. The result is slow, shallow learning that wastes the benefit of depth.
6. What are the assumptions of linear regression?
Linear regression assumes a specific structure in the residuals, the gap between actual and predicted values. The four assumptions:
- Residuals are independent.
- The relationship between predictors and target is linear.
- Residual variance is constant across the predictor range.
- Residuals are normally distributed.
7. Explain the difference between linear and logistic regression.
Linear regression predicts continuous values; logistic regression predicts categories. A pricing engine that estimates a price from competitor prices and demand uses linear regression; a model that predicts a movie's genre from its features uses logistic regression.
8. How do you evaluate an LLM's performance?
LLM evaluation combines automatic metrics with task-level checks, and it now shows up directly in ML interviews.
"Perplexity measures how surprised the model is when it predicts the next word, and lower is better. Cross-entropy measures how well the predicted probabilities match the true labels."
Strong answers pair these with task-specific evaluation and human review rather than a single number.
Practice machine learning interview questions
Work through real questions, then get feedback under interview conditions:
- Practice ML questions with community answers
- Take the ML engineer interview course
- Start a mock interview
Machine learning interview FAQs
How do I prepare for a machine learning interview?
Prepare for a machine learning interview by working through the four rounds in order: ML concepts, coding, system design, and behavioral. For a full study plan and timeline, use the machine learning interview prep guide, and practice against real questions in Exponent's ML engineer course.
What are the four types of machine learning?
The four types of machine learning are supervised learning, unsupervised learning, semi-supervised learning, and reinforcement learning. Supervised learning trains on labeled data, unsupervised learning finds structure in unlabeled data, semi-supervised learning combines both, and reinforcement learning learns from reward signals.
Are LLM and GenAI questions now part of ML engineer interviews?
Recent ML engineer interviews have included GenAI and LLM questions and prompts such as designing an inference batching system (asked at Anthropic) and evaluating an LLM's performance (asked at Snap), alongside classic ML theory.
How is an ML system design interview different from an ML coding interview?
An ML system design interview asks you to architect a complete ML product (data, model, serving, monitoring, scale), while an ML coding interview asks you to implement a specific algorithm or preprocessing task in code.
How do I explain an ML project in an interview?
Explain an ML project by stating the problem, the dataset, the model you chose, the evaluation metrics, and the results, then name the main challenge and how you handled it. Keep it structured so the interviewer can follow your reasoning and your specific contribution.
Book time with a Machine Learning Engineer coach
- Mock interviews
- Career coaching
- Resume review
Learn everything you need to ace your machine learning interviews.
Exponent is the fastest-growing tech interview prep platform. Get free interview guides, insider tips, and courses.
Create your free accountRelated Courses

Machine Learning Engineer Interview Prep Course

Related Blog Posts
Machine Learning System Design Interview (2026 Guide)
Complete Guide to Machine Learning Engineering Interviews

How to Become a Machine Learning Engineer

